Cs50-Ai-Machine-Learning
Machine Learning
- 机器学习为计算机提供数据,而非确切的指令,通过这些数据,计算机学习去识别模式并自行执行
监督学习
- 监督学习是指计算机基于输入-输出对数据集来学习函数映射。
- 监督意味着这些数据已经有了确切的标签or分类
分类学习:最近邻居分类
- 为相关变量分配最近的观察值
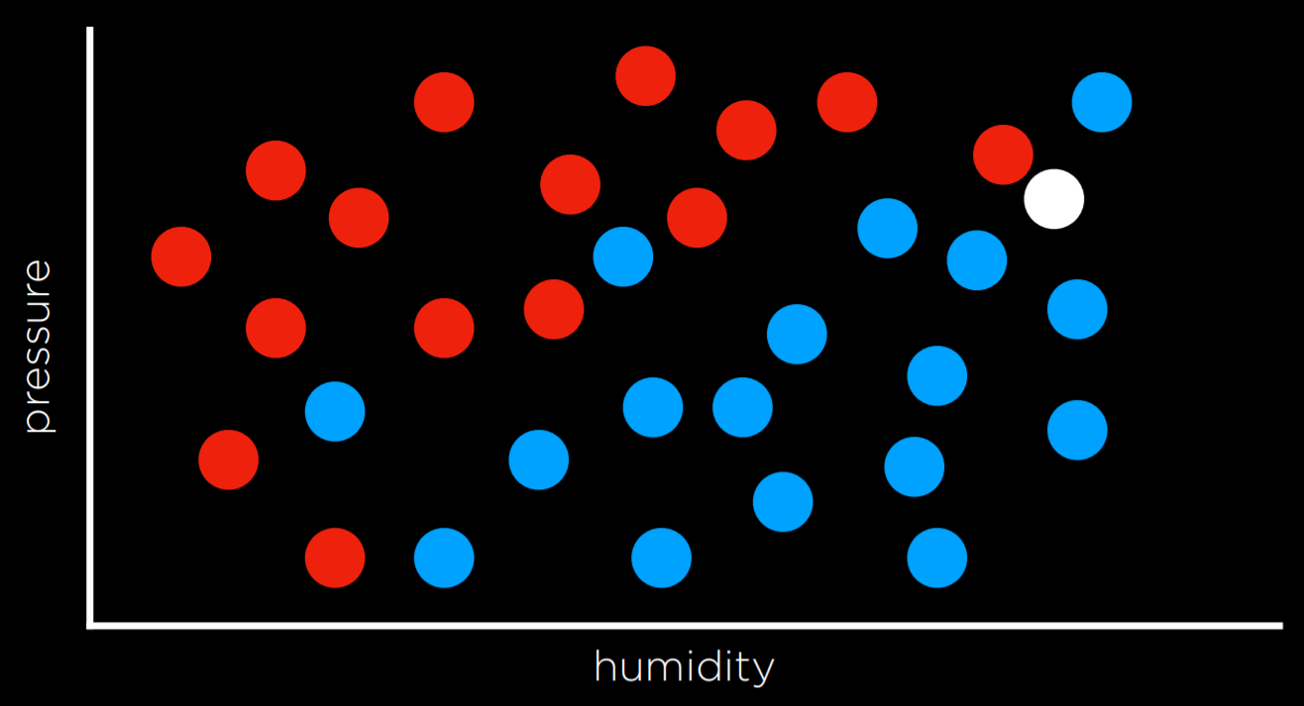
比如这张图,根据最近观察值策略,可能会认为他是红色的;然而从更大角度来看,它周围蓝色点居多,我们直觉地认为,蓝色可能是更好的预测,即时最近的观察值是红色的(局限性or不准确)
- 优化:k最近邻居分类,根据点最近的k个邻居的值来判断。缺点是需要消耗计算力去测量各个点到相关点的距离。(进一步可以通过剪枝或更符合的数据结构加速)
- 选择k值:k是一个超参数,表示需要考虑的最近邻居的数量。k的选择会影响模型的性能:
- 如果k太小,模型可能会过拟合,对噪声敏感。
- 如果k太大,模型可能会欠拟合,忽略数据的局部特征。
- 选择k值:k是一个超参数,表示需要考虑的最近邻居的数量。k的选择会影响模型的性能:
感知器学习
- 神经网络:由一个或多个神经元组成,而一个神经元包含输入、输出和内部处理器
- 感知器(perceptron):单层感知器(包含输入和输出层,且二者直接相连)、多层感知器(多层计算)
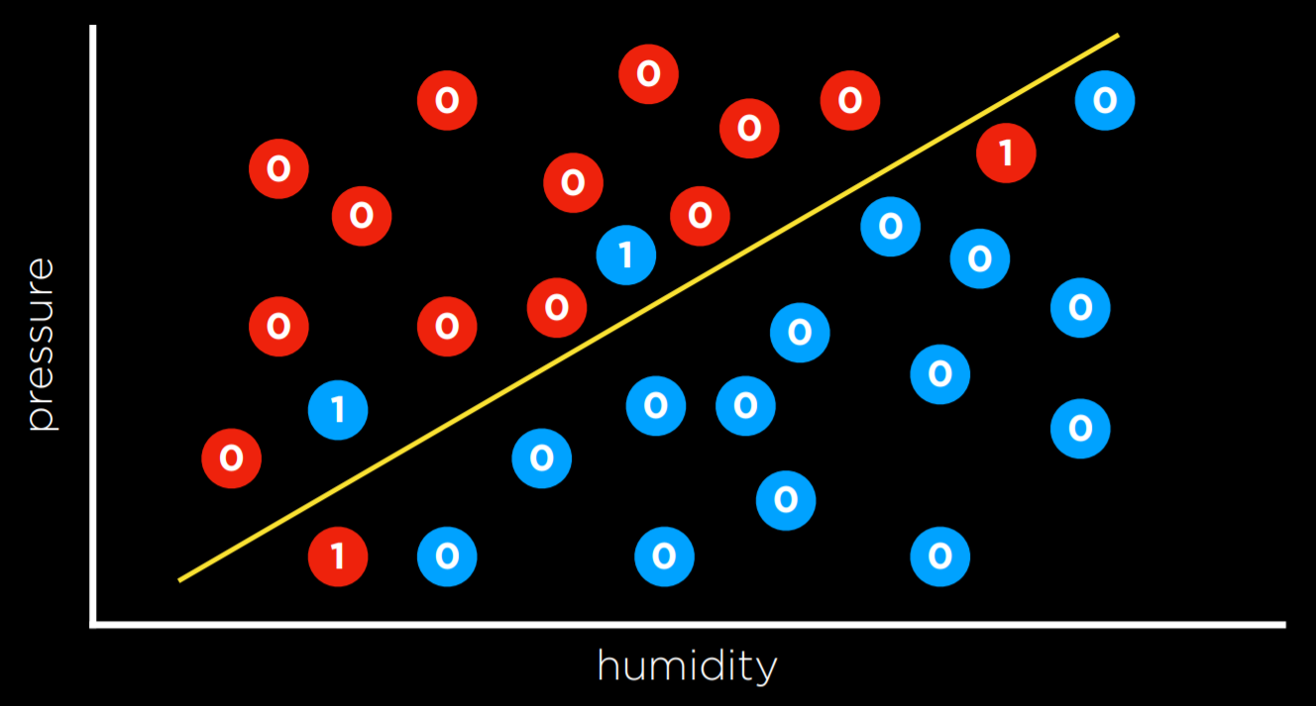
- 与最近邻策略相反,解决分类问题的另一种方法是将数据作为一个整体来查看,并尝试创建一个决策边界–二分类的线性分类模型
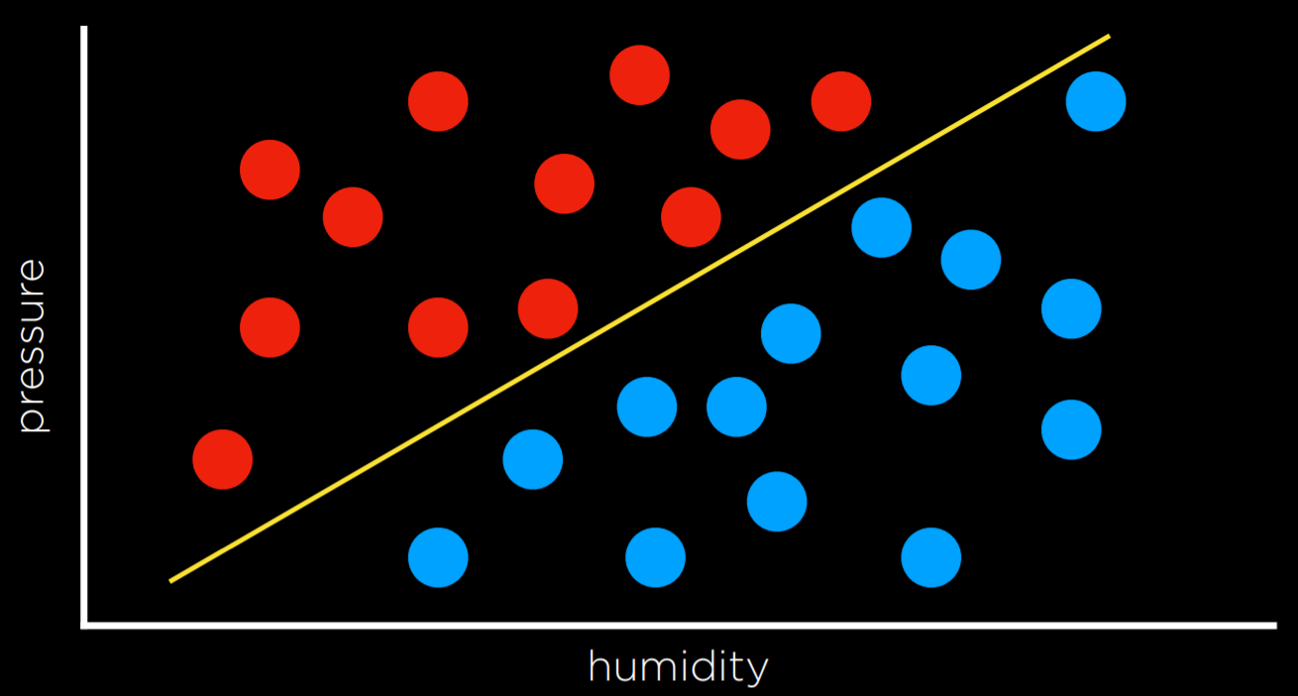
缺点:数据很混乱,很少能画一条线并将类整齐地划分为两个观测值而没有任何错误。
将各个参数与对应的权重相乘之后相加,输入到激活函数,通过判断是否超过阈值得到期望。
例子:
- 输入–x1=humidity(湿度);x2=pressure(压力);函数h(x1,x2)
- 该函数对每个输入进行加权,并添加一个常数,产生如下的线性方程:
- Rain w₀ + w₁x₁ + w₂x₂ ≥ 0
- No Rain otherwise
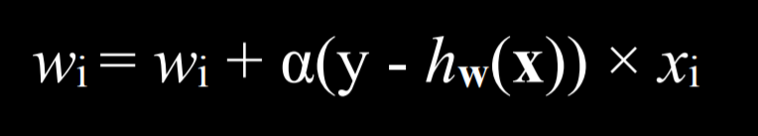
这里的y代表观测值,而h(x)代表估计值,如果他们误差较大,说明要调整这个数据的权重
如果它们相同,则整个项等于零,因此权重不会改变。如果我们低估了(在观察到 Rain 时调用 No Rain),那么括号中的值将为 1,权重将增加新的值α学习系数。如果我们高估(在观察到 No Rain 时调用 Rain),则括号中的值将为 -1,权重将减少 x 的值,缩放 α。α越高,每个新事件对权重的影响就越大。
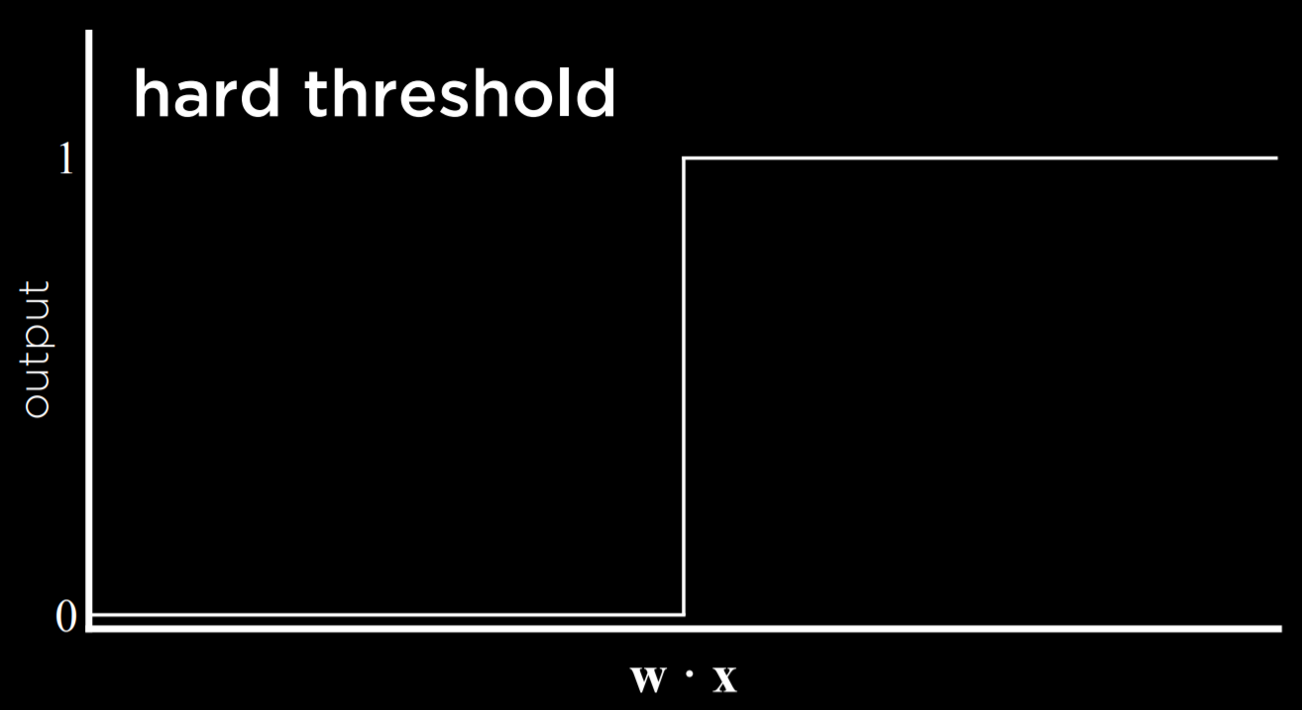
结果是一个阈值函数,一旦超过设定的值函数值就会发生跳跃
- 硬性阈值
- 软性阈值
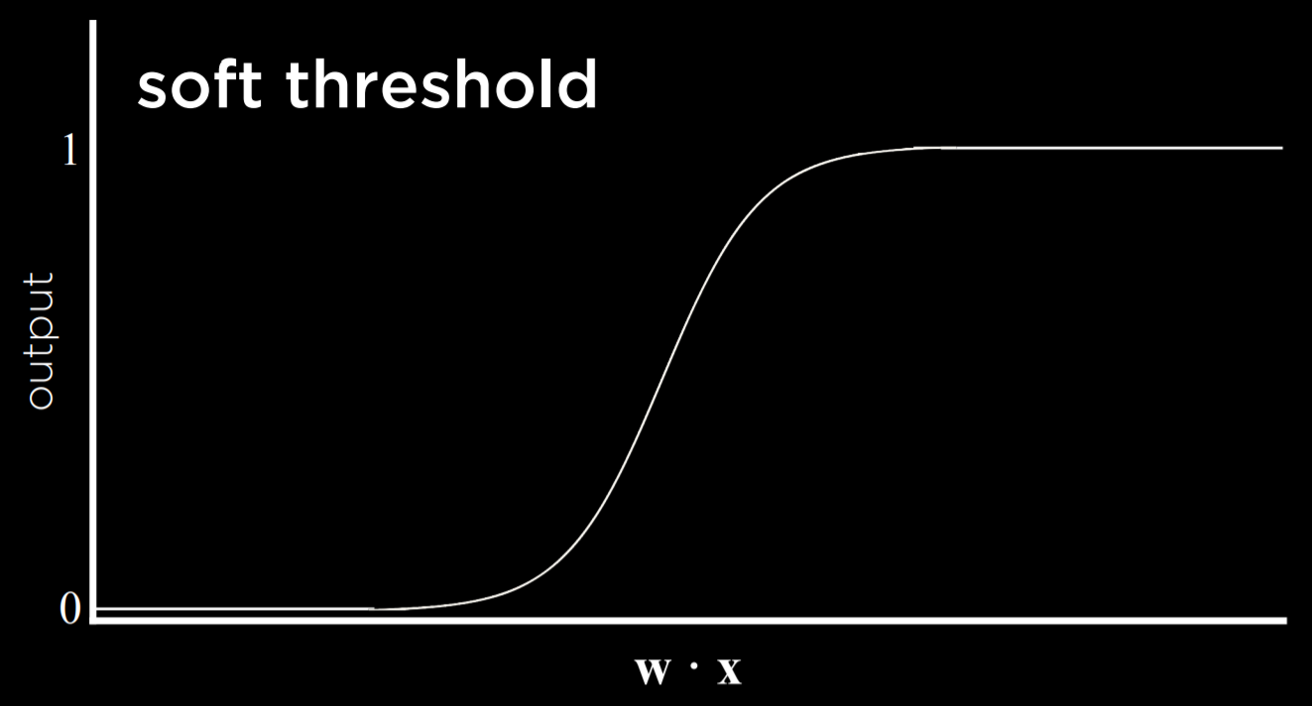
- 硬性阈值
软性阈值会存在中间过渡的值
支持向量机
这种方法是在决策边界附件使用一个额外的向量(支持向量),以便在分离数据时做出最佳决策–Maximum Margin Separator
优点:可以表示两个维度以上的决策边界,以及非线性决策边界
回归
回归是函数的监督学习任务,它将输入点映射到连续值。
目标不是在观察类型之间进行分离,而是根据输入预测输出的值
损失函数
0-1损失函数
- L(预测,损失):当实际=预测,则L=0;否则,L=1
- 预测连续值时,可以使用L1和L2损失函数,更加看重每个预测域观测值之间的差异程度。
- L1:L(实际,预测)=|实际-预测|
- L2:L(实际,预测)=|实际-预测|²
过拟合
过拟合是指模型与训练数据的你和非常好,以至于无法推广到其他数据集。
正则化
正则化是惩罚更复杂的假设以支持更简单、更一般的假设的过程。我们使用正则化来避免过拟合。
cost(h) = loss(h) + λcomplexity(h)
测试我们是否过度拟合模型的一种方法是使用 Holdout Cross Validation。在这种技术中,我们将所有数据一分为二:训练集和测试集。我们在训练集上运行学习算法,然后查看它对测试集中数据的预测能力如何。这里的想法是,通过测试训练中未使用的数据,我们可以衡量学习的泛化程度。
保持交叉验证的缺点是,我们无法使用一半的数据来训练模型,因为它用于评估目的。解决这个问题的一种方法是使用 k-Fold\ 交叉验证。在这个过程中,我们将数据分成 k 个集合。我们运行训练 k 次,每次都省略一个数据集并将其用作测试集。我们最终对模型进行了 k 种不同的评估,我们可以对模型进行平均并估计我们的模型如何泛化而不会丢失任何数据。
强度学习
在每次行动过后,agent会得到反馈(正反馈或负反馈
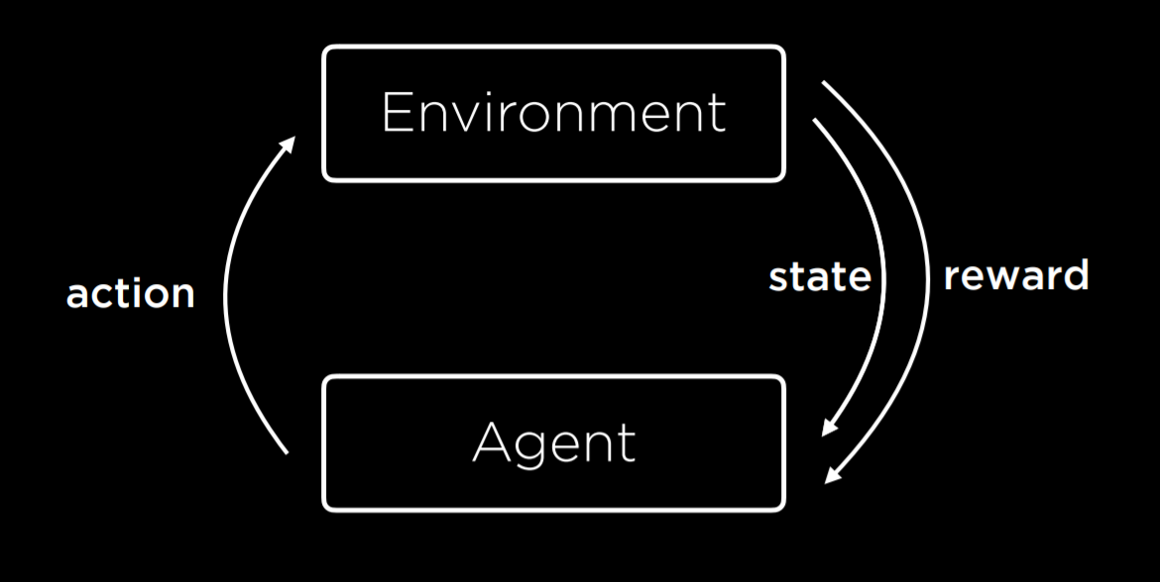
马尔可夫决策过程
- Set of states S
- Set of actions Actions(S)
- Transition model P(s’ | s, a)
- Reward function R(s, a, s’)
Q学习
函数 Q(s, a) 输出在状态 s 下采取行动 a 的值的估计值
模型从所有估计值等于0开始,当执行作并收到奖励时,该函数会执行两项作:
1) 它根据当前奖励和预期的未来奖励估计 Q(s, a) 的值,以及
2) 更新 Q(s, a) 以同时考虑旧估计值和新估计值。
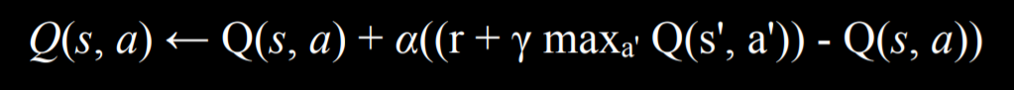
训练强化学习模型的另一种方法是,不是在每次移动时提供反馈,而是在整个过程结束时提供反馈
非监督学习
- 没有人为进行分类,只有输入数据,AI会学习这些数据中的模式
聚类:
获取输入数据并将其组织成组,以便相似的对象最终属于同一组
K-means聚集
它映射一个空间中的所有数据点,然后在空间中随机放置 k 个集群中心(由程序员决定多少个,这是我们在左侧看到的起始状态)。每个集群中心只是空间中的一个点。然后,每个聚类都会分配最接近其中心的所有点,而不是任何其他中心(这是中间的图片)。然后,在迭代过程中,聚类中心移动到所有这些点的中间(右侧的状态),然后再次将点重新分配给现在最靠近它们的聚类。当重复该过程后,每个点都保持在与之前相同的集群中时,我们已经达到了平衡,算法结束了,给我们留下了在集群之间划分的点。
Project
shopping
背景
当用户在线购物时,并非所有人最终都会购买东西。事实上,在线购物网站的大多数访问者可能不会在网络浏览会话期间进行购买。不过,购物网站能够预测用户是否打算进行购买可能很有用:也许向用户显示不同的内容,例如,如果网站认为用户不打算完成购买,则向用户显示折扣优惠。网站如何确定用户的购买意向?这就是机器学习的用武之地。
您在此问题中的任务是构建一个最近邻分类器来解决此问题。给定有关用户的信息 — 他们访问了多少个页面,他们是否在周末购物,他们正在使用什么 Web 浏览器等 — 您的分类器将预测用户是否会进行购买。您的分类器不会完全准确 — 完美地模拟人类行为是一项远远超出本课程范围的任务 — 但它应该比随机猜测要好。为了训练您的分类器,我们将为您提供来自某个购物网站的一些数据,这些数据来自大约 12000 个用户会话。
我们如何衡量此类系统的准确性?如果我们有一个测试数据集,我们可以对数据运行分类器,并计算我们正确分类用户意图的时间比例。这将为我们提供一个准确率。但这个数字可能有点误导。例如,想象一下,如果大约 15% 的用户最终完成了购买。如果分类器始终预测用户不会完成购买,那么,我们将衡量为 85% 的准确率:它唯一错误分类的用户是 15% 的用户。虽然 85% 的准确率听起来不错,但这似乎不是一个非常有用的分类器。
相反,我们将测量两个值:灵敏度(也称为“真阳性率”)和特异性(也称为“真阴性率”)。敏感度是指正确识别的正面示例的比例:换句话说,正确识别完成购买的用户比例。特异性是指被正确识别的负面示例的比例:在这种情况下,未完成购买但被正确识别的用户比例。因此,我们之前的 “always guess no” 分类器将具有完美的特异性 (1.0),但没有灵敏度 (0.0)。我们的目标是构建一个在这两个指标上都执行合理的分类器。
理解
shopping.csv文件中是数据集
- 前六列衡量了用户在会话中访问的不同类型页面
Administrative、Informational、ProductRelated列指示下的值代表用户访问过多少这类型的页面_Duration列指示了用户留存时间BounceRates,ExitRates和PageValues衡量来自谷歌评估的有关用户访问的页面信息SpecialDay评估了用户访问日期和特殊日期的接近程度- 还有一些有关用户的属性
VisitorType指示了是回头客或新用户Weekend是布尔值,代表是否在周末进行访问- 最后还有一个指示用户是否购买的列
Revenue
shopping.py文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22def main():
# Check command-line arguments
if len(sys.argv) != 2:
sys.exit("Usage: python shopping.py data")
# Load data from spreadsheet and split into train and test sets
evidence, labels = load_data(sys.argv[1])
X_train, X_test, y_train, y_test = train_test_split(
evidence, labels, test_size=TEST_SIZE
)
# Train model and make predictions
model = train_model(X_train, y_train)
predictions = model.predict(X_test)
sensitivity, specificity = evaluate(y_test, predictions)
# Print results
print(f"Correct: {(y_test == predictions).sum()}")
print(f"Incorrect: {(y_test != predictions).sum()}")
print(f"True Positive Rate: {100 * sensitivity:.2f}%")
print(f"True Negative Rate: {100 * specificity:.2f}%")load_data函数用来加载数据和分割数据train_model函数是用来训练的,会对测试集的输入做出预测evaluate函数用于检测敏感度和特异性
特性
load_data 函数
load_data 函数应接受一个 CSV 文件名作为参数,打开该文件,并返回一个元组 (evidence, labels)。evidence 应是一个包含所有数据点证据的列表,labels 应是一个包含所有数据点标签的列表。
由于每一行数据对应一个证据和一个标签,evidence 列表和 labels 列表的长度应等于 CSV 文件中的行数(不包括标题行)。列表的顺序应与用户在电子表格中的顺序一致。也就是说,evidence[0] 应是第一个用户的证据,labels[0] 应是第一个用户的标签。
evidence 列表中的每个元素应是一个长度为 17 的列表,对应电子表格中除最后一列(标签列)外的每一列。证据列表中的值应与电子表格中的列顺序一致。你可以假设 shopping.csv 中的列顺序始终不变。
请注意,为了构建最近邻分类器,所有数据都必须是数值类型。确保你的值具有以下类型:
Administrative,Informational,ProductRelated,Month,OperatingSystems,Browser,Region,TrafficType,VisitorType, 和Weekend应为int类型。Administrative_Duration,Informational_Duration,ProductRelated_Duration,BounceRates,ExitRates,PageValues, 和SpecialDay应为float类型。Month应为 0(一月)到 11(十二月)。VisitorType应为 1(返回访客)或 0(非返回访客)。Weekend应为 1(用户在周末访问)或 0(否则)。
labels 中的每个值应为整数 1(用户完成购买)或 0(否则)。
例如,第一个证据列表的值应为 [0, 0.0, 0, 0.0, 1, 0.0, 0.2, 0.2, 0.0, 0.0, 1, 1, 1, 1, 1, 1, 0],第一个标签的值应为 0。
更加顺序化:
1 | |
train_model 函数
train_model 函数应接受一个证据列表和一个标签列表,并返回一个基于该训练数据训练的 scikit-learn 最近邻分类器(k=1 的 k-最近邻分类器)。
请注意,我们已经为你导入了 from sklearn.neighbors import KNeighborsClassifier。你应在此函数中使用 KNeighborsClassifier。
evaluate 函数
evaluate 函数应接受一个标签列表(测试集中用户的真实标签)和一个预测列表(分类器预测的标签),并返回两个浮点值 (sensitivity, specificity)。
sensitivity应为 0 到 1 之间的浮点值,表示“真正例率”:实际为正例的标签中被准确识别的比例。specificity应为 0 到 1 之间的浮点值,表示“真负例率”:实际为负例的标签中被准确识别的比例。
你可以假设每个标签为 1(正例,用户完成购买)或 0(负例,用户未完成购买)。你可以假设真实标签列表至少包含一个正例和一个负例。
指导
load_data函数:- 使用 Python 的
csv模块或pandas库读取 CSV 文件。 - 遍历每一行数据,将除最后一列外的所有列转换为适当的类型,并存储在
evidence列表中。 - 将最后一列(标签列)转换为整数,并存储在
labels列表中。 - 确保所有数据的类型正确,特别是
Month、VisitorType和Weekend的转换。
- 使用 Python 的
train_model函数:- 使用
KNeighborsClassifier创建一个 k=1 的最近邻分类器。 - 使用
fit方法将证据和标签作为训练数据拟合模型。 - 返回训练好的模型。
- 使用
evaluate函数:- 计算真正例(True Positives, TP)、真负例(True Negatives, TN)、假正例(False Positives, FP)和假负例(False Negatives, FN)。
- 使用公式
sensitivity = TP / (TP + FN)计算敏感度。 - 使用公式
specificity = TN / (TN + FP)计算特异性。 - 返回计算得到的敏感度和特异性。
注意事项
- 确保数据类型转换正确,特别是
Month、VisitorType和Weekend的转换。 - 在
evaluate函数中,确保正确处理边界情况,例如所有预测都为正例或负例的情况。 - 使用适当的库函数和方法来简化代码,例如
pandas的read_csv函数和scikit-learn的KNeighborsClassifier。
通过这些步骤,你应该能够成功实现 load_data、train_model 和 evaluate 函数。