本文最后更新于 2025-04-29T11:39:52+08:00
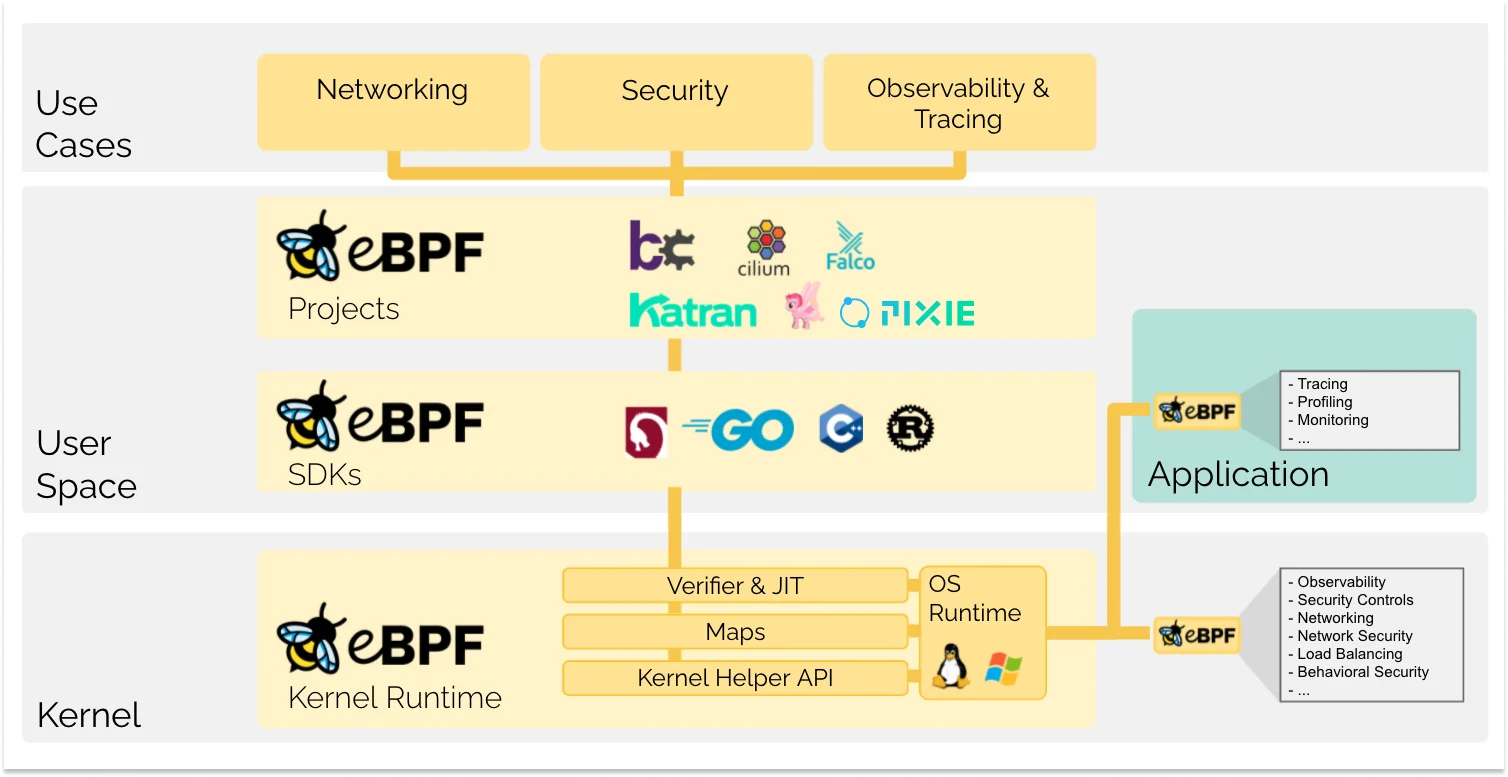
Chapter1 Introduction 什么是eBPF
eBPF可以在特权上下文中(如kernel)运行==沙盒==程序。用于安全有效地扩展内核的功能 ,而无需通过更改内核源代码或加载内核模块的方式来实现。
eBPF从根本上改变了这个方式,通过允许在操作系统中运行沙盒程序 的方式,应用程序开发人员可以运行eBPF程序 ,以便在运行时向操作系统添加额外的功能 。然后在JIT编译器 和验证引擎 的帮助下,操作系统确保它像本地编译的程序一样具备安全性和执行效率
eBPF最初代表了伯克利包过滤器 (Berkeley Packet Filter) ,但现在能做的更多了,缩写不再有意义。最初的eBPF有时候被称为cBPF(经典BPF)。
eBPF简介 resources: BPF 和 XDP 参考指南 — Cilium 1.17.2 文档 什么是 eBPF ? An Introduction and Deep Dive into the eBPF Technology (中文版)
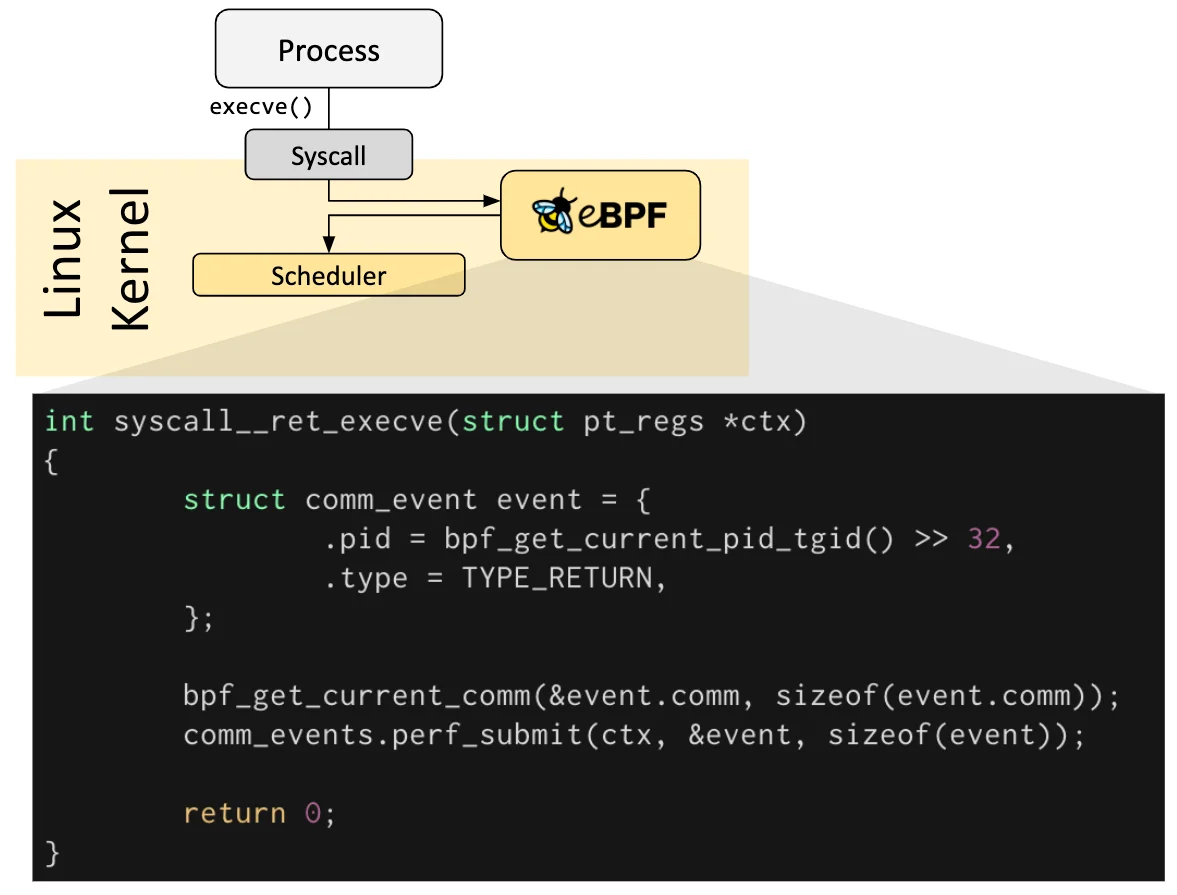
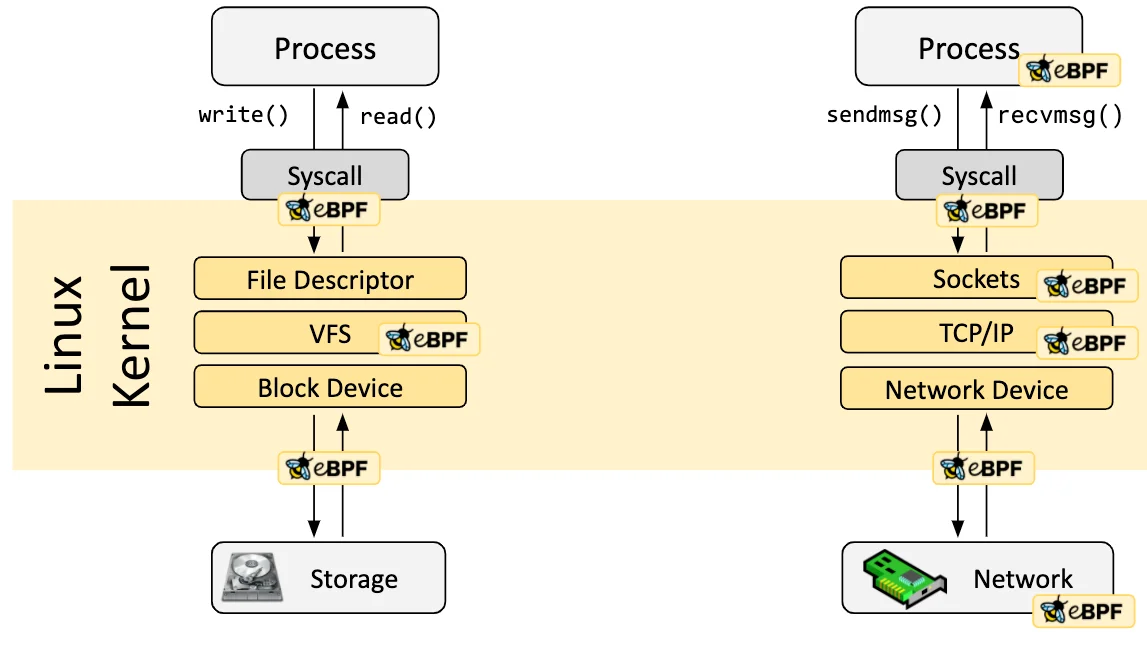
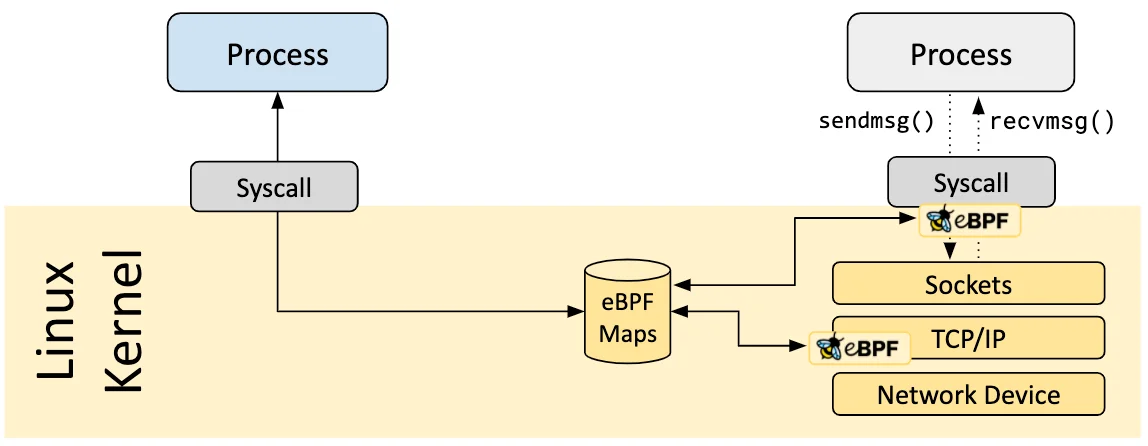
钩子概览 eBPF 程序是事件驱动 的,当内核或应用程序通过某个钩子点 时运行。预定义的钩子 包括系统调用、函数入口/退出、内核跟踪点、网络事件等。创建内核探针 (kprobe)或用户探针 (uprobe),以便在内核或用户应用程序的几乎任何位置附加 eBPF 程序 。
eBPF的核心钩子位置:
Kprobes/Uprobes :动态跟踪内核或用户空间函数调用Tracepoints :静态内核事件跟踪点(如系统调用、调度事件)TC(Traffic Control) :在网络流量控制层 处理数据包Socket Filters :过滤或监控套接字数据
如何编写eBPF程序 使用cilium、bcc或bpftrace 这样子的项目间接使用,这些项目提供了 eBPF 之上的抽象,不需要直接编写程序,而是提供了指定基于意图的来定义实现的能力,然后用 eBPF 实现。
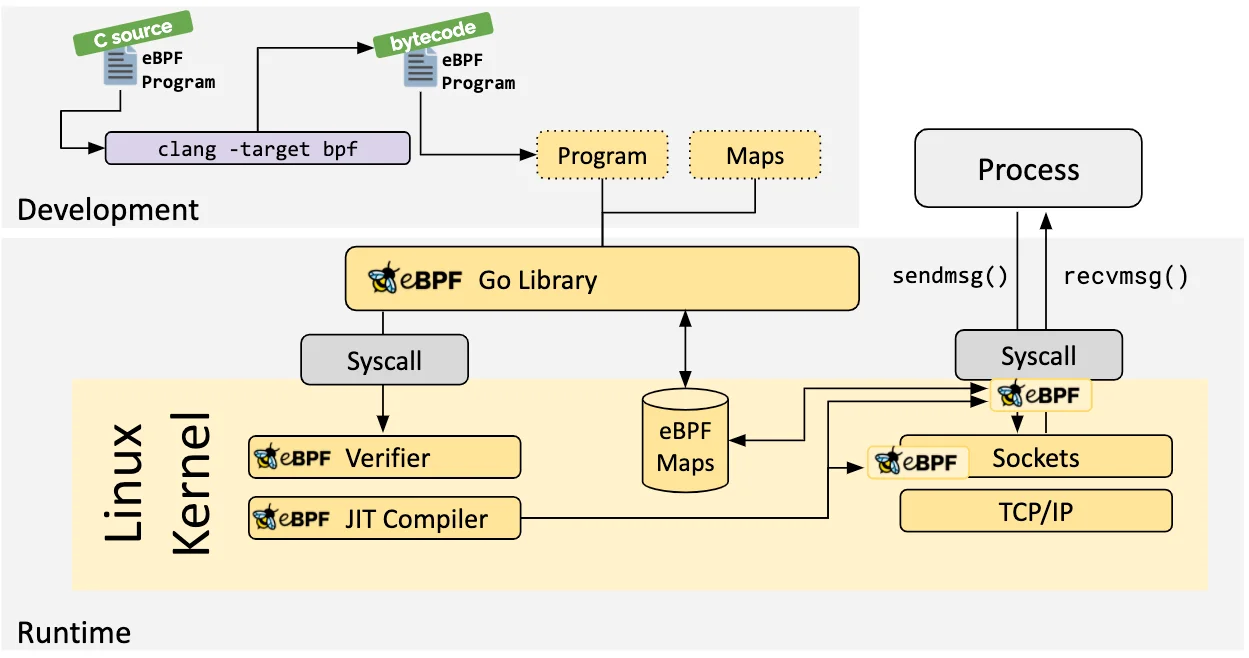
加载器和校验架构 确定所需的钩子后,可以使用 bpf 系统调用 将 eBPF 程序加载到 Linux 内核中。这通常是使用一个可用的 eBPF 库来完成的。
当层序被加载到Linux内核中时,它在被附加到所请求的钩子上之前要经过两个步骤:
验证:验证步骤用来确保eBPF程序可以安全运行
加载eBPF程序的进程==必须要所需的能力(特权)==,除非启用非特权eBPF ,否则只有特权进程可以加载eBPF程序
eBPF程序不会崩溃或者对系统造成损害
eBPF程序一定会运行至结束
JIT编译
JIT (Just-in-Time) 编译步骤将程序的通用字节码转换为机器特定的指令集 ,用以优化程序的执行速 度。这使得 eBPF 程序可以像本地编译的内核代码或作为内核模块加载的代码一样高效地运行。
Maps eBPF 程序的其中一个重要方面是共享和存储 所收集的信息和状态的能力。从 eBPF 程序访问 ,也可以通过系统调用 从用户空间中的应用程序访问 。
Helper调用 eBPF 程序不直接调用内核函数。这样做会将 eBPF 程序绑定到特定的内核版本,会使程序的兼容性复杂化。而对应地,eBPF 程序改为调用 helper 函数达到效果,这是内核提供的通用且稳定的 API。
可用的 helper 调用集也在不断发展迭代中。一些 helper 调用的示例:
生成随机数
获取当前时间日期
eBPF map 访问
获取进程 / cgroup 上下文
操作网络数据包及其转发逻辑
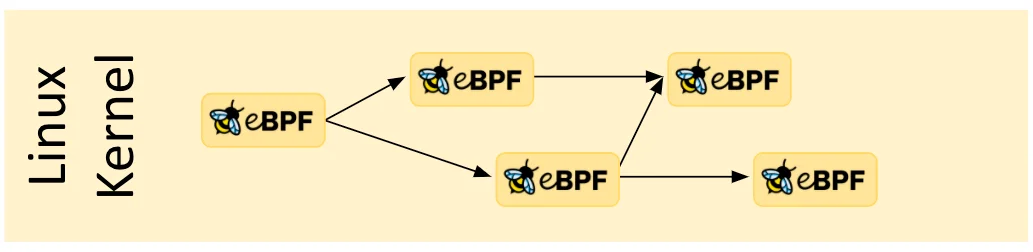
尾调用和函数调用 eBPF 程序可以通过尾调用和函数调用的概念来组合。函数调用允许在 eBPF 程序内部完成定义和调用函数。尾调用可以调用和执行另一个 eBPF 程序并替换执行上下文,类似于 execve() 系统调用对常规进程的操作方式。
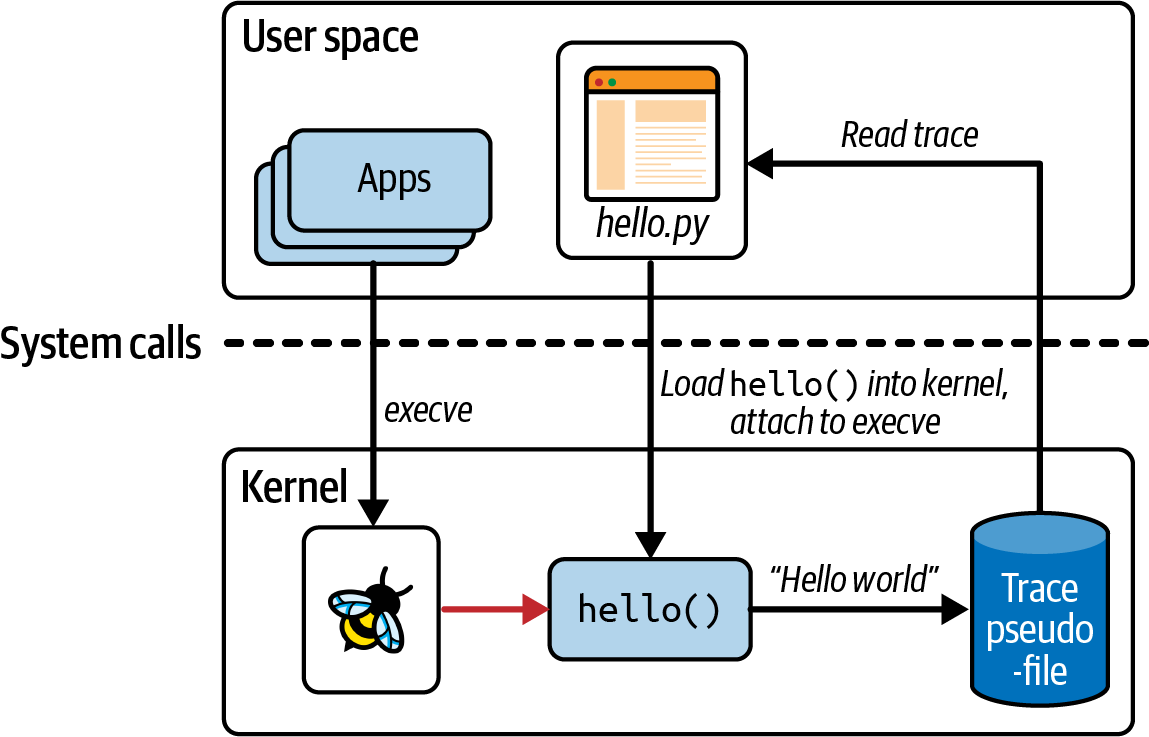
Chapter 2:简单运行Hello World Hello world code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #!/usr/bin/python3 import BPFr"" " int hello(void *ctx) { bpf_trace_printk(" Hello World!"); return 0; } " "" "execve" )"hello" )
命令:
1 2 3 4 5 6 7 8 chmod +x ~/ebpf-programs/hello.pysudo ~/ebpf-programs/hello.pysudo python3 ~/ebpf-programs/hello.py
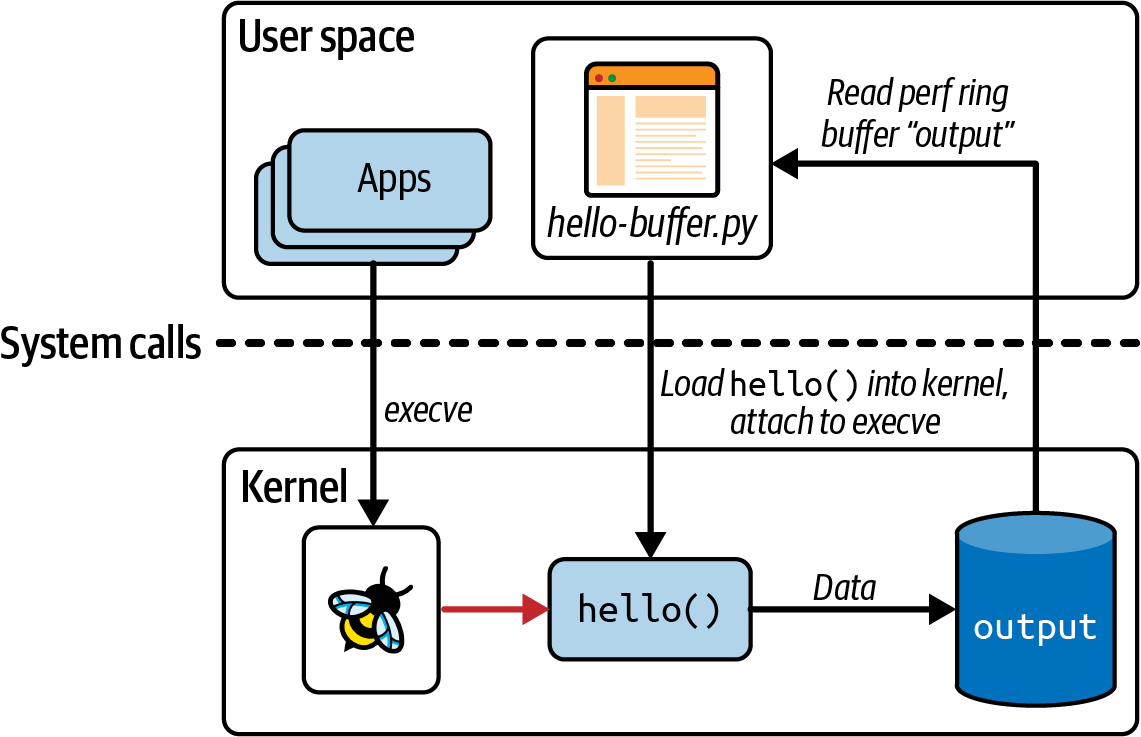
解读 这段代码由两部分组成:运行在内核中的eBPF程序 (被””” “””包住的部分)本身,以及将eBPF程序加载到内核并读取其生成的跟踪的用户空间代码
hello.py是用户空间,hello()是运行在内核中的eBPF程序。
[!NOTE]
辅助函数bpf_trace_printk():可以用来编写消息/打印信息;辅助函数是eBPF程序可以调用与系统交互的函数
跟踪输出:bpf_trace_printk()总是将输出发送到相同的预定义的伪文件位置:/sys/kernel/debug/tracing/trace_pipe。但如果有多个eBPF程序会导致混乱(都保存到同样的地方)=>引入BPF Maps
[!NOTE]
eBPF程序可以动态改变系统的行为,一旦负载到事件上就可以由效果-
BPF Maps
map是一种可以在用户空间访问 的数据结构
maps可以用来在多个eBPF程序 中共享数据,或者在用户空间 应用程序和运行的eBPF代码 之间通信
用户空间写入配置信息到eBPF程序,以便检索
由一个eBPF程序存储状态以便后续由另一个程序检索
eBPF程序将结果或metrics写入map,以便用户空间应用呈现/检索结果
Hash Table Map C程序部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 BPF_HASH(counter_table);int hello (void *ctx) {0 ;0xFFFFFFFF ;if (p != 0 ) {return 0 ;
BPF_HASH()是bcc用于定义hash table的宏bpf_get_current_uid_gid()是一个辅助函数,用于获得触发k探针事件的进程ID(保存到了64位的低32位中,高32位保留给group ID(但是这部分被masked out了))lookup(&uid) 在哈希表中查找具有与用户ID相匹配的键的条目,并返回一个指向对应值的指针
bcc framework部分和前面helloworld基本相同,读取信息部分需要修改为从哈希表中读取
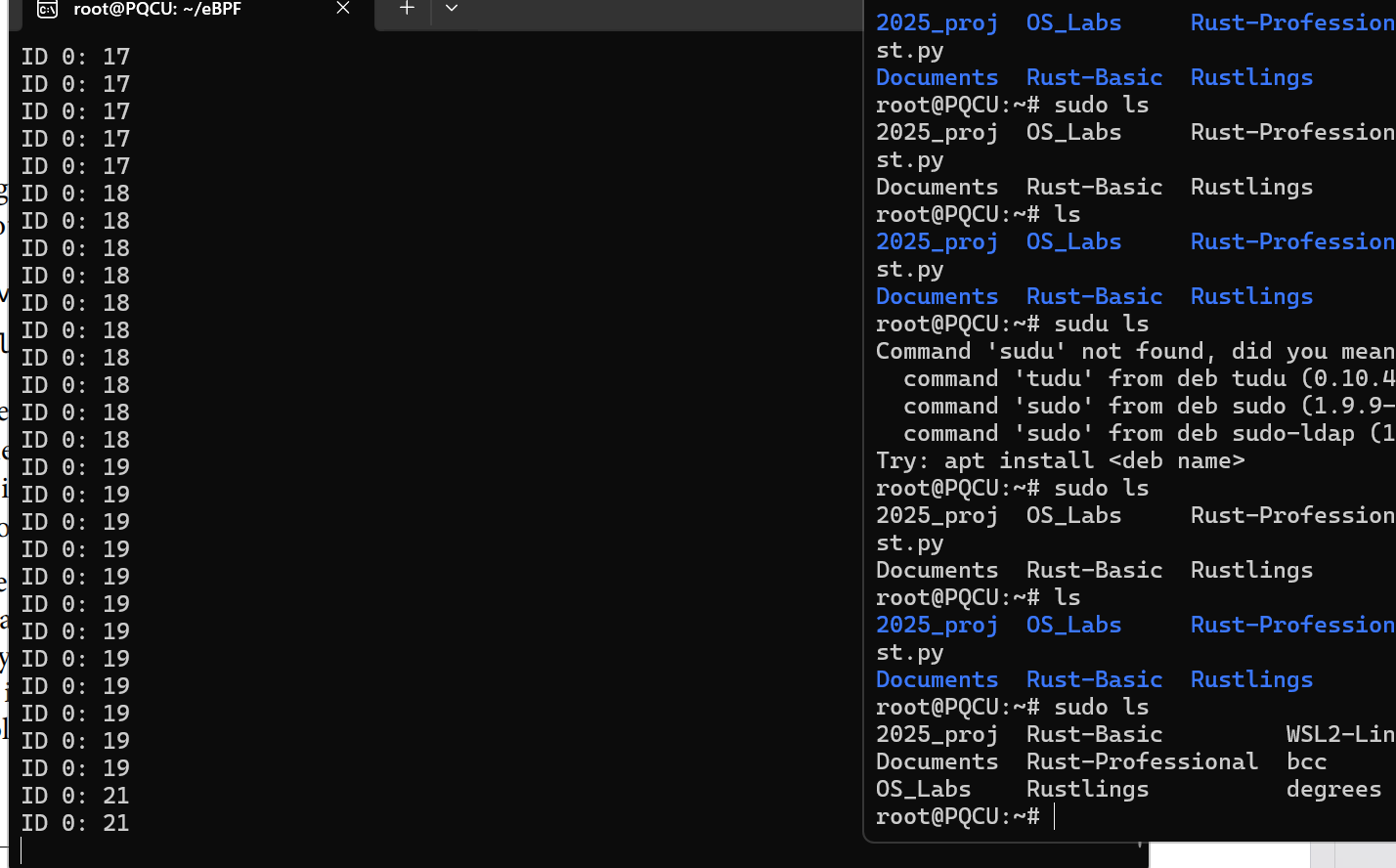
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from bcc import BPFfrom time import sleepr""" BPF_HASH(counter_table); int hello(void *ctx) { u64 uid; u64 counter = 0; u64 *p; uid = bpf_get_current_uid_gid() & 0xFFFFFFFF; p = counter_table.lookup(&uid); if (p != 0) { counter = *p; } counter++; counter_table.update(&uid, &counter); return 0; } """ "execve" )"hello" )while True :2 )"" for k,v in b["counter_table" ].items():f"ID {k.value} : {v.value} \t" print (s)
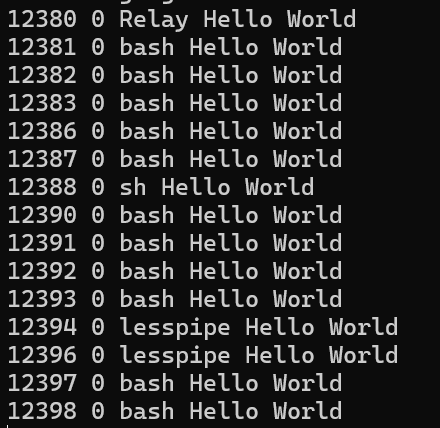
运行结果:
Perf and Ring Buffer Maps
允许以我们选择的结构将数据写入到perf环缓冲区映射中
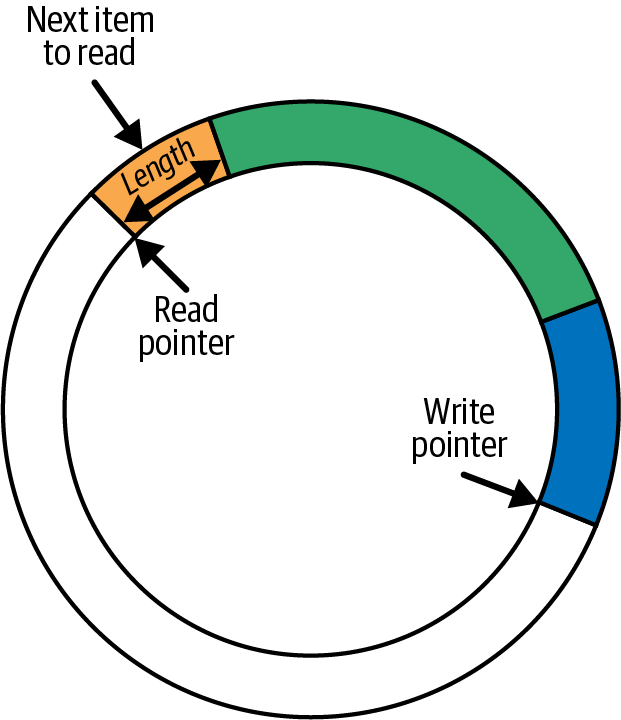
环缓冲区可以看做是逻辑组织在环中的内存,由单独的写、读指针。任意长度的数据被写入指针的任何位置,长度信息包含在该数据的头 中。对于读取操作,从读取指针所在的任何位置读取数据,使用头来确定要读取多少数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from bcc import BPFr""" BPF_PERF_OUTPUT(output); struct data_t { int pid; int uid; char command[16]; char message[12]; }; int hello(void *ctx) { struct data_t data = {}; char message[12] = "Hello World"; data.pid = bpf_get_current_pid_tgid() >> 32; data.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF; bpf_get_current_comm(&data.command, sizeof(data.command)); bpf_probe_read_kernel(&data.message, sizeof(data.message), message); output.perf_submit(ctx, &data, sizeof(data)); return 0; } """ "execve" )"hello" )def print_event (cpu, data, size ): "output" ].event(data)print (f"{data.pid} {data.uid} {data.command.decode()} {data.message.decode()} " )"output" ].open_perf_buffer(print_event) while True :
BPF_PERF_OUTPUT用于创建一个map(从内核传递消息到用户空间–map output)bpf_get_current_pid_tgid():获取触发词eBPF程序的进程IDbpf_get_current_comm():用于获取在创建execve系统共享的进程中运行的可执行文件;这是一个字符串,传递参数方法不太一样(要传递地址和长度)
Tail Calls
尾调用可以调用并执行另一个eBPF程序,并替换执行上下文,且不会返回原始位置
long bpf_tail_call(void *ctx, struct bpf_map *prog_array_map, u32 index)
ctx允许将上下文从调用的eBPF程序传递给被调用者。
prog_array_map是一种BPF_MAP_TYPE_PROG_ARRAY类型的eBPF映射,它包含一组标识eBPF程序的文件描述符。
index指示应该调用哪一组eBPF程序prog_array_map.call(ctx, index)
code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 from bcc import BPFimport ctypes as ctr""" BPF_PROG_ARRAY(syscall, 500); int hello(struct bpf_raw_tracepoint_args *ctx) { int opcode = ctx->args[1]; syscall.call(ctx, opcode); bpf_trace_printk("Another syscall: %d", opcode); return 0; } int hello_exec(void *ctx) { bpf_trace_printk("Executing a program"); return 0; } int hello_timer(struct bpf_raw_tracepoint_args *ctx) { int opcode = ctx->args[1]; switch (opcode) { case 222: bpf_trace_printk("Creating a timer"); break; case 226: bpf_trace_printk("Deleting a timer"); break; default: bpf_trace_printk("Some other timer operation"); break; } return 0; } int ignore_opcode(void *ctx) { return 0; } """ "sys_enter" , fn_name="hello" )"ignore_opcode" , BPF.RAW_TRACEPOINT)"hello_exec" , BPF.RAW_TRACEPOINT)"hello_timer" , BPF.RAW_TRACEPOINT)"syscall" )for i in range (len (prog_array)):59 )] = ct.c_int(exec_fn.fd)222 )] = ct.c_int(timer_fn.fd)223 )] = ct.c_int(timer_fn.fd)224 )] = ct.c_int(timer_fn.fd)225 )] = ct.c_int(timer_fn.fd)226 )] = ct.c_int(timer_fn.fd)