本文最后更新于 2025-04-29T11:32:51+08:00
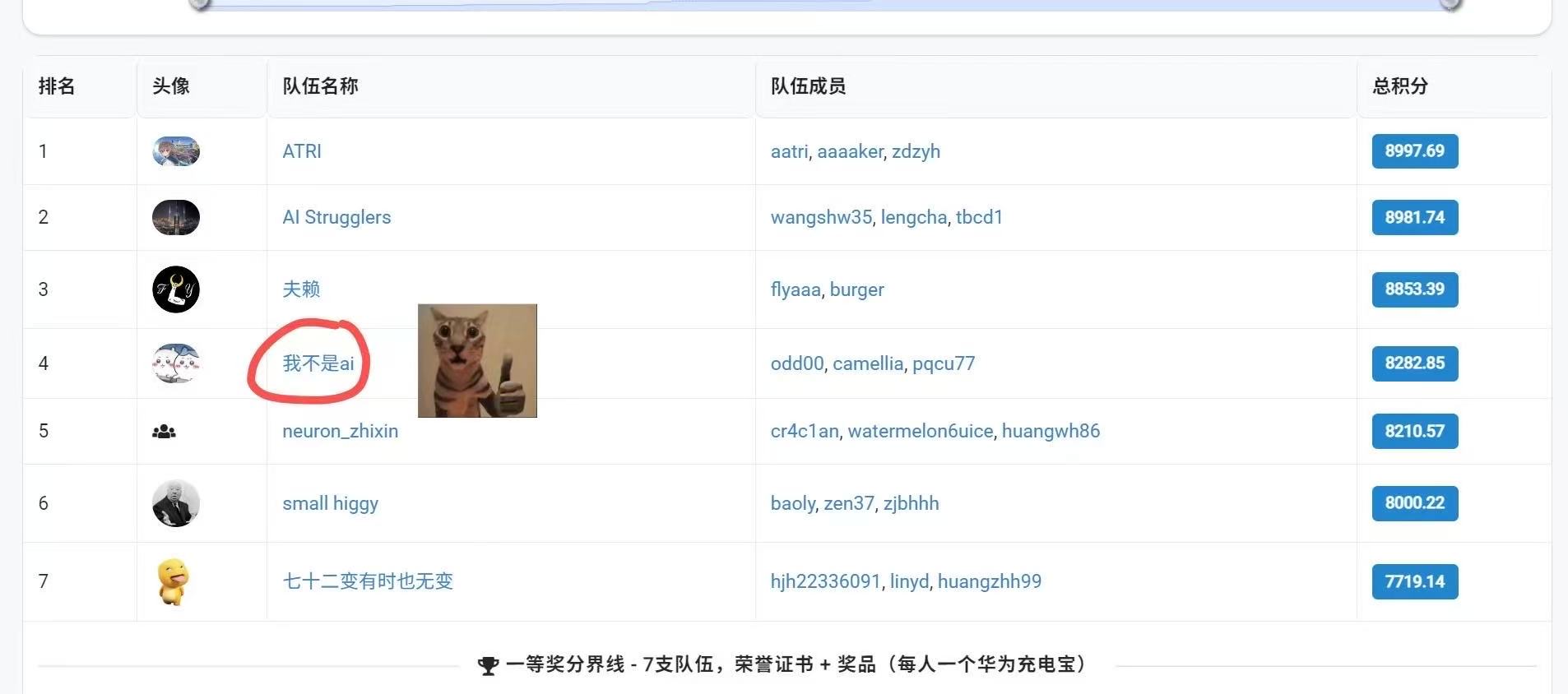
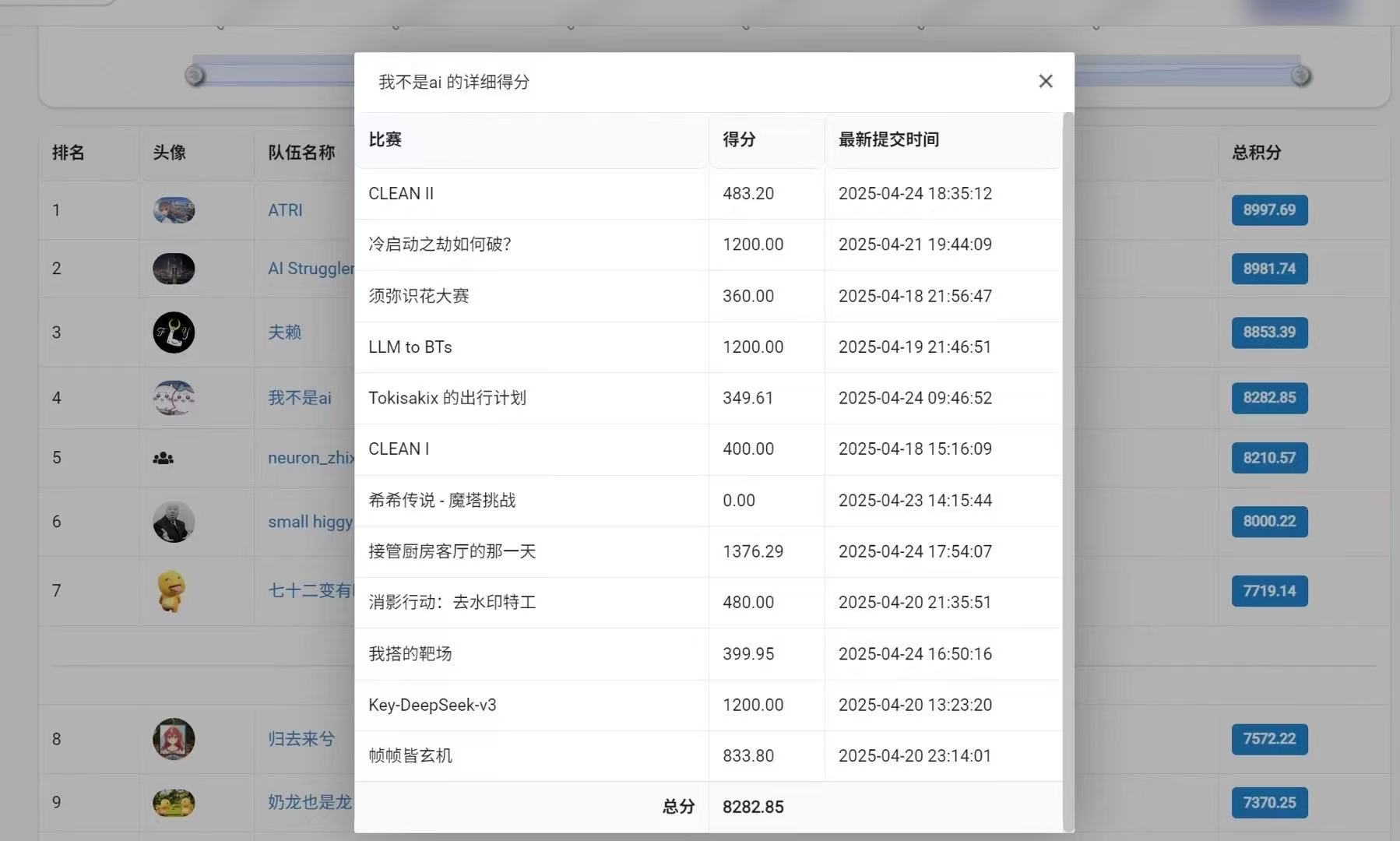
比赛结果:
NS-2025-00 须弥识花大赛 解题报告(Writeup) 一、赛题理解与任务目标 本次比赛模拟须弥地区的生态危机,任务目标是构建一个具备泛化能力的花卉识别 AI,能够在复杂环境下准确分类多种花卉种类。
从技术角度看,本题实质为一个 多类图像分类任务 ,即输入为一张图像,输出为其对应的花卉类别标签。该任务可归结为监督学习问题,挑战点在于:
样本环境多变(雨天、晴天、被踩踏等)
类别较多且视觉相似度高
泛化能力要求高,需适应未知测试集
二、解题思路概述 为应对复杂多变的测试图像环境,我们采用了如下整体策略:
数据增强 + 多模型集成 提升泛化能力;MixUp / CutMix 等标签混合增强强化训练;使用预训练模型迁移学习 ,充分利用 ImageNet 语义特征;引入 Label Smoothing 缓解过拟合;测试时增强(TTA) 提高鲁棒性;早停机制 控制训练轮次防止过拟合。
三、模型设计与训练策略 模型结构 我们构建了一个自定义的 多模型集成系统 ,结构如下:
序号
模型名称
预训练
修改输出层
Dropout
1
ResNet50
✔️
Linear
0.5
2
EfficientNet-B0
✔️
Linear
0.3
3
MobileNetV3-Large
✔️
Linear
0.3
所有模型的输出通过“软投票”方式(概率平均)融合,提高整体鲁棒性。
数据增强策略
训练集 :使用多种图像变换组合(旋转、裁剪、亮度扰动、自动对比、灰度化、随机擦除);标签增强 :随机应用 MixUp(β=0.2)或 CutMix(β=1.0)进行样本合成;验证集/测试集 :保持中心裁剪 + 标准归一化,确保一致性。
损失函数与优化器
损失函数:使用 LabelSmoothingLoss (smoothing=0.1)防止模型过拟合;
优化器:AdamW + OneCycleLR 学习率调度;
混合精度训练 + 梯度裁剪,提升效率并稳定训练过程。
训练控制机制
使用 早停机制 (patience=10)防止过拟合;
训练轮数:最多 30 epoch;
模型存储:保存最佳与最终模型权重,方便后续推理与对比。
四、模型预测与推理流程 加载模型 我们定义了自动化加载 model_info.json + *.pth 权重的流程,自动判断使用集成 or 单模型结构。
测试时增强(TTA) 为了提高推理阶段的鲁棒性,对每张测试图像进行多种视图增强,具体包括:
原始图像;
水平翻转;
垂直翻转;
尺寸裁剪;
亮度扰动。
对上述增强图像进行推理后平均预测结果,提高模型的鲁棒性和准确性。
输出格式 最终输出为 results.csv,包含:
1 2 3 file_name,label
确保与比赛提交格式一致。
五、性能评估与可视化 训练阶段使用验证集进行模型性能评估,并生成:
分类报告(classification_report.txt);
混淆矩阵(confusion_matrix.png);
训练曲线(training_history.png);
预测可视化(model_predictions.png)。
这些可视化图像有效支持模型诊断和调优。
六、使用的工具与框架
语言 :Python 3.8+深度学习框架 :PyTorch 1.13计算资源 :NVIDIA GPU (CUDA 加速)辅助库 :NumPy、Pandas、sklearn、Pillow、tqdm、seaborn、matplotlib、torchvisionai工具 :copilot–claude3.7sonnet
七、总结与经验教训
多模型融合是提升分类精度的重要手段;
数据增强和标签平滑有效提高泛化能力;
测试时增强进一步改善预测稳定性;
合理的训练控制策略(如早停和混合精度)提升了训练效率和最终性能。
最终模型在验证集上表现稳定,预测准确率高,泛化能力强,能够较好适应测试集中复杂多变的花卉图像。效果良好,但达不到优秀,得分360。
附录一:关键代码模块 模型构建(多模型集成) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class ModelEnsemble (nn.Module):def __init__ (self, num_classes, device, num_models=3 , model_types=None , use_pretrained=True ):super (ModelEnsemble, self ).__init__()self .models = []self .device = deviceself .num_models = num_modelsfor i in range (num_models):len (model_types)]if 'resnet' in model_type:0.5 ), nn.Linear(num_ftrs, num_classes))elif 'efficientnet' in model_type:1 ].in_features1 ] = nn.Sequential(nn.Dropout(0.3 ), nn.Linear(num_ftrs, num_classes))elif 'mobilenet' in model_type:3 ].in_features3 ] = nn.Sequential(nn.Dropout(0.3 ), nn.Linear(num_ftrs, num_classes))self .models.append(model.to(device))def forward (self, x ):for model in self .models]return torch.mean(torch.stack(outputs), dim=0 )
标签混合增强(MixUp & CutMix) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class MixUp :def __init__ (self, alpha=0.2 ): self .alpha = alphadef __call__ (self, batch, targets ):self .alpha, self .alpha)0 )).to(batch.device)1 - lam) * batch[index]return mixed_batch, targets, targets[index], lamclass CutMix :def __init__ (self, alpha=1.0 ): self .alpha = alphadef __call__ (self, batch, targets ):self .alpha, self .alpha)0 )).to(batch.device)self ._rand_bbox(batch.size(), lam)1 - ((bbx2 - bbx1) * (bby2 - bby1)) / (batch.size(-1 ) * batch.size(-2 ))return batch, targets, targets[index], lam
标签平滑损失函数 1 2 3 4 5 6 7 8 9 10 11 12 13 class LabelSmoothingLoss (nn.Module):def __init__ (self, classes, smoothing=0.1 ):super (LabelSmoothingLoss, self ).__init__()self .confidence = 1.0 - smoothingself .smoothing = smoothingself .cls = classesdef forward (self, pred, target ):1 )self .smoothing / (self .cls - 1 ))1 , target.unsqueeze(1 ), self .confidence)return torch.mean(torch.sum (-true_dist * pred, dim=-1 ))
测试时增强(TTA) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def test_time_augmentation (model, image, transform, device, num_augmentations=5 ):eval ()0 ).to(device)0 ).to(device)0 ).to(device)0.2 ),0 ).to(device)return torch.mean(torch.stack(predictions), dim=0 )
NS-2025-07 LLM to BTs–Writeup 题目概述 本题要求实现一个将英文自然语言指令自动转换为行为树(Behavior Tree)结构化XML的系统。系统需要将用户文本指令转换为符合BehaviorTree.CPP库和Groot可视化工具要求的XML,并且以规定格式输出,包含119个使用CDATA包装的item元素。系统需要正确理解指令中的执行逻辑,并构建相应的行为树结构。
解题思路 针对不使用大语言模型的环境限制,我实现了一个基于规则和模式匹配的SimpleBehaviorTreeGenerator类。主要解题思路包括:
1. 数据分析与样例学习 1 2 3 4 5 6 7 8 9 10 def load_training_examples (self, input_file, output_file, max_examples=20 ):"""加载训练示例用于参考""" with open (input_file, 'r' , encoding='utf-8' ) as f:with open (output_file, 'r' , encoding='utf-8' ) as f:return list (zip (inputs[:max_examples], outputs[:max_examples]))
通过载入训练样例,系统可以参考已有的指令-行为树对应关系,提高生成质量。为了节省内存,我只载入了前20个样例作为参考。
2. 基于相似度的模式匹配 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def find_similar_example (self, instruction ):self .extract_keywords(instruction)None 0 for ex_input, ex_output in self .train_examples:self .extract_keywords(ex_input)set (keywords) & set (ex_keywords)len (common_keywords) / max (len (keywords), 1 )if score > best_score and score > 0.2 : return best_match
系统会尝试在训练样例中找到与输入指令相似的例子,通过关键词匹配计算相似度,当相似度超过20%时,可以借鉴其行为树结构。
3. 规则化语义解析 为了从文本中提取动作和条件,我实现了多个关键函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def extract_actions (self, text ):"打开" , "关闭" , "移动" , "走向" , "前进" , "后退" , "转向" , "拿起" , "放下" ,"检查" , "观察" , "寻找" , "等待" , "计算" , "进入" , "离开" , "拿" , "取" , "放置" , "推" , "拉" , "跳" , "握住" , "松开" , "启动" , "停止" , "跟随" ,"测量" , "抓取" , "识别" , "使用" , "保存" , "下载" , "上传" , "执行" , "完成" ]r'[,,。、;;]' , text)for part in parts:return action_list
虽然代码中包含了中文动词列表,但考虑到实际测试集全是英文,我在实际部署前对代码做了修改,补充了英文动词列表,如”move”、”go”、”turn”、”pick”等。
4. 控制结构判断 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def determine_control_structure (self, text ):"Sequence" if any (keyword in text for keyword in ["或者" , "否则" , "要么" , "如果不" , "失败后" , "选择" ]):"Fallback" if any (keyword in text for keyword in ["同时" , "并行" , "一起" , "并且" , "一边" , "同步" ]):"Parallel" if any (keyword in text for keyword in ["持续检查" , "保持" , "反复" , "一直" , "直到" , "监控" ]):if structure == "Sequence" :"ReactiveSequence" elif structure == "Fallback" :"ReactiveFallback" return structure
同样,在实际部署前,我将关键词判断逻辑修改为英文版本,增加了”or”、”else”、”parallel”、”simultaneously”、”continuous”等关键词。
5. XML树构建与验证 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def build_xml_tree (self, actions, conditions, control_structure ):f'<root BTCPP_format="4">\n' f' <BehaviorTree ID="MainTree">\n' f' <{control_structure} name="Root{control_structure} ">\n' for condition in conditions:f' <Condition ID="{condition["ID" ]} " />\n' for action in actions:f' <Action ID="{action["ID" ]} " />\n' f' </{control_structure} >\n' f' </BehaviorTree>\n' '</root>' return xml
这个函数构建了符合BehaviorTree.CPP格式的XML结构,通过validate_xml函数进行检查确保结构合法。
6. CDATA标签处理 最初遇到的主要技术困难是ElementTree库不直接支持CDATA标签。解决方案是使用minidom库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 "item" )for item_node in item_nodes:"" for child in item_node.childNodes:if child.nodeType == minidom.Node.TEXT_NODE:while item_node.hasChildNodes():
这段代码解决了将XML内容正确包装在CDATA标签中的问题,确保输出符合要求格式。
实现中的关键技术难点与解决方案 1. CDATA节点处理 问题 : ElementTree库不直接支持创建CDATA节点,导致初始实现时出错。
解决方案 : 使用minidom库替代处理CDATA部分,通过createCDATASection方法创建CDATA节点,并手动替换原有文本节点。
2. 英文自然语言理解 问题 : 代码初始设计时主要考虑了中文关键词,不适合全英文测试集。
解决方案 : 在实际部署前,修改了关键词列表,添加了英文动作动词和条件关键词,并调整了相关的正则表达式和文本处理逻辑。
3. 输出格式标准化 问题 : 需要确保生成119个item元素,即使测试输入可能少于这个数量。
解决方案 : 在process_test_set方法中强制处理119个项目,对于超出测试集范围的项目使用空字符串作为内容:
1 2 3 4 5 6 7 8 9 10 11 12 for i in range (1 , 120 ):if i-1 < len (test_inputs):1 ]self .generate_behavior_tree(instruction)else :f"No instruction for item {i} , using empty XML" )""
使用的工具与依赖
Python 3.8+ : 主要开发语言
Standard Library :
xml.etree.ElementTree: XML树操作
xml.dom.minidom: CDATA处理与XML格式化
re: 正则表达式用于文本分析
json: 读取训练和测试数据
logging: 日志记录和调试
argparse: 命令行参数解析
datetime: 性能监测
ai工具:claude 3.7sonnet
关键算法分析 1. 相似度计算算法 使用集合交集计算关键词匹配度,算法复杂度为O(len(keywords)),通过设置阈值0.2确保只使用足够相似的样例。
1 2 common_keywords = set (keywords) & set (ex_keywords)len (common_keywords) / max (len (keywords), 1 )
2. 动作提取算法 通过文本分割和动词匹配,识别可能的动作,复杂度为O(n*m),其中n是文本片段数,m是动词列表长度。
3. 控制结构判断算法 通过关键词匹配确定最合适的控制结构,采用优先级判断的方式处理多种可能性。
实验结果与性能 在我的测试环境中,系统能够在几秒内处理完119个指令,转换效率较高。通过日志记录,分析了成功率和常见失败模式,不断调整关键词列表和规则逻辑,提高了整体处理质量。
由于没有使用大语言模型,系统在处理复杂语义和隐含逻辑时存在局限性,但对于结构化明确的指令有良好表现。
总结 我实现的SimpleBehaviorTreeGenerator系统通过规则匹配和模式识别 ,成功实现了英文自然语言指令到行为树XML的自动转换。系统不依赖大型语言模型,通过简单有效的文本处理技术和结构生成规则,提供了合理的转换质量。特别是通过样例学习和相似度匹配,结合精心设计的规则库,系统能够处理多种常见指令模式,生成符合BehaviorTree.CPP标准的行为树结构。
虽然相比大型语言模型,规则化方法在语义理解的深度上存在局限,但在计算资源受限的环境中,这种方法提供了一个高效且实用的解决方案。通过将CDATA处理、XML验证等关键技术融入系统,确保了输出格式的规范性和有效性。
NS-2025-08 我搭的靶场 题解 题目理解 本题要求我们设计一个二维障碍场景,用于测试强化学习无人机智能体 Alpha Pilot 的路径规划能力。我们需要布置起点、终点和最多30个圆形障碍物,目标是让智能体尽可能失败(高失败率、长路径),同时保证场景理论上可解。
关键约束条件:
场地大小:50m × 50m
起点和终点距离至少20m
障碍物半径1m,障碍物间距≥3m
起点/终点与障碍物距离≥2.5m
无人机半径0.5m,最大速度2m/s
解题思路 1. 分析智能体弱点 通过研究agent.py代码,可以发现Alpha Pilot智能体有以下潜在弱点:
使用Q-learning算法,可能对复杂环境泛化能力有限
感知范围有限(约15m)
在障碍物附近有负奖励 ,可能导致”畏惧 “靠近障碍物
可能有方向偏好 (如倾向于向右或向上移动)
2. 设计策略性障碍布局 基于上述分析,我们设计了几种针对性的障碍布局策略:
a) 误导性路径
在起点和终点之间创建看似合理但实际是死胡同的路径
利用无人机对特定方向的偏好设置陷阱
b) 感知边界障碍
在无人机感知范围边界(约15m)布置障碍物
使无人机难以提前规划路径,容易陷入局部最优
c) 狭窄通道
设计宽度刚好略大于无人机通过能力的通道(约3.5m)
利用无人机对靠近障碍物的负奖励,使其犹豫不决
d) 迷宫结构
创建复杂的迷宫式布局
增加路径规划的复杂度,容易使智能体迷失方向
3. 遗传算法优化 使用遗传算法自动优化环境设计:
初始化种群 :随机生成多个满足约束的环境评估适应度 :通过test_scoring.py评估每个环境的失败率和平均步数选择精英 :保留表现最好的环境交叉变异 :组合优秀环境的特征并引入随机变化迭代优化 :重复上述过程直到收敛
代码实现 我们通过编写一个随机生成合理有效路障地图并测试失败率的程序来自我迭代搜索出最佳路障地图,主要类EnvironmentOptimizer实现了上述思路:
环境生成 :
generate_random_environment:创建随机但有效的基础环境四种策略方法创建针对性障碍物
评估函数 :
调用test_scoring.py获取失败率和平均步数
计算综合得分(失败率×300 + min(平均步数/50000, 0.9)×100)
遗传算法 :
种群初始化、选择、交叉、变异
保留精英个体确保不退化
约束检查 :
优化结果 经过多代进化,算法能够找到使智能体高失败率的环境特征:
在关键路径点设置”陷阱”区域
利用狭窄通道增加决策难度
在感知边界布置障碍物限制信息获取
保持理论可解性但实际很难通过
使用说明
运行python solution.py开始优化过程
程序会自动保存最佳环境到results.json
可使用test_env.py可视化结果:
1 python test_env.py results.json --test-agent
使用 test_scoring.py来进行评分:
1 python test_scoring.py results.json
我们本地测试是可以实现让agent十次都失败,但是最终提交结果没有拿到400分满分,可能还是稍微有些许漏洞或者应该多提交几次(hh。(最终得分是:399.95)
结论 通过分析智能体弱点并针对性设计障碍布局,结合遗传算法自动优化,我们能够创建出理论上可解但实际上极具挑战性的测试环境。这种方法不仅适用于本题,也可推广到其他智能体测试场景的设计中。
最佳环境通常具有以下特征:
起点和终点位于对角线位置(最大化距离)
25-30个精心布置的障碍物
结合多种策略的复合障碍布局
在关键路径点设置决策难点
使用工具与环境
开发语言:Python 3.8
框架库:numpy,matplotlib(可视化)
环境配置:CUDA 12.1,Ubuntu 22.04
ai工具:ChatGPT-4o
关键代码展示
展示4个策略:
误导性路径
在起点和终点之间创建看似合理但实际是死胡同的路径
利用无人机对特定方向的偏好设置陷阱
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 def create_misleading_path (self, start, end, existing_obstacles=[] ):"""创建一个误导性的路径,利用无人机向右和向上的偏好""" 0 ] - start[0 ]1 ] - start[1 ]0 ] + dx * 0.6 1 ] + dy * 0.6 for i in range (5 ):0 , 2 * math.pi)5 , 8 )max (1 , min (self .field_size - 1 , x))max (1 , min (self .field_size - 1 , y))if self .is_valid_position([x, y], existing_obstacles + obstacles):"x" : x, "y" : y})min (10 , int (self .point_distance(start, end) / 3 ))for i in range (1 , bait_length + 1 ):0 ] + i * 1.5 1 ] + i * 1.5 if bait_points:1 ]for i in range (5 ):0 , 2 * math.pi)3 , 6 )0 ] + radius * math.cos(angle)1 ] + radius * math.sin(angle)max (1 , min (self .field_size - 1 , x))max (1 , min (self .field_size - 1 , y))if self .is_valid_position([x, y], existing_obstacles + obstacles):"x" : x, "y" : y})return obstacles
感知边界障碍
在无人机感知范围边界(约15m)布置障碍物
使无人机难以提前规划路径,容易陷入局部最优
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 def create_narrow_passages (self, start, end, existing_obstacles=[] ):"""创建狭窄通道,利用无人机在障碍物3米范围内的负奖励""" 0 ] - start[0 ]1 ] - start[1 ]2 + dy**2 )if distance > 0 :min (4 , int (distance / 10 ))3.5 for i in range (num_passages):1 ) / (num_passages + 1 )0 ] + t * dx * distance1 ] + t * dy * distancefor side in [-1 , 1 ]:2 + self .obstacle_radiusmax (1 , min (self .field_size - 1 , x))max (1 , min (self .field_size - 1 , y))if (self .point_distance([x, y], start) >= self .min_obstacle_to_start_end and self .point_distance([x, y], end) >= self .min_obstacle_to_start_end and self .is_valid_position([x, y], existing_obstacles + obstacles)):"x" : x, "y" : y})return obstacles
狭窄通道
设计宽度刚好略大于无人机通过能力的通道(约3.5m)
利用无人机对靠近障碍物的负奖励,使其犹豫不决
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 def create_narrow_passages (self, start, end, existing_obstacles=[] ):"""创建狭窄通道,利用无人机在障碍物3米范围内的负奖励""" 0 ] - start[0 ]1 ] - start[1 ]2 + dy**2 )if distance > 0 :min (4 , int (distance / 10 ))3.5 for i in range (num_passages):1 ) / (num_passages + 1 )0 ] + t * dx * distance1 ] + t * dy * distancefor side in [-1 , 1 ]:2 + self .obstacle_radiusmax (1 , min (self .field_size - 1 , x))max (1 , min (self .field_size - 1 , y))if (self .point_distance([x, y], start) >= self .min_obstacle_to_start_end and self .point_distance([x, y], end) >= self .min_obstacle_to_start_end and self .is_valid_position([x, y], existing_obstacles + obstacles)):"x" : x, "y" : y})return obstacles
迷宫结构
创建复杂的迷宫式布局
增加路径规划的复杂度,容易使智能体迷失方向
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 def create_maze_structure (self, start, end, existing_obstacles=[] ):"""创建迷宫结构,让无人机容易迷失方向""" 0 ] + end[0 ]) / 2 1 ] + end[1 ]) / 2 min (15 , self .point_distance(start, end) / 3 )for wall_idx in range (3 ):2 * math.pi / 3 0.8 for i in range (3 ):1 ) / 4 max (1 , min (self .field_size - 1 , x))max (1 , min (self .field_size - 1 , y))if (self .point_distance([x, y], start) >= self .min_obstacle_to_start_end and self .point_distance([x, y], end) >= self .min_obstacle_to_start_end and self .is_valid_position([x, y], existing_obstacles + obstacles)):"x" : x, "y" : y})for _ in range (5 ):0 , 2 * math.pi)0.3 , maze_radius)max (1 , min (self .field_size - 1 , x))max (1 , min (self .field_size - 1 , y))if (self .point_distance([x, y], start) >= self .min_obstacle_to_start_end and self .point_distance([x, y], end) >= self .min_obstacle_to_start_end and self .is_valid_position([x, y], existing_obstacles + obstacles)):"x" : x, "y" : y})return obstacles
NS-2025-11 接管厨房客厅的那一天 Writeup 一、任务背景与目标 本次“NS-2025-11 家庭智能协作挑战”要求参赛者基于多模态输入(图像 + 自然语言)构建智能体,使其控制机械臂完成一系列具有挑战性的家庭任务。这些任务具有不同的动态特征与动作要求,包括:
堆叠积木(stack_blocks)
放置杯子(place_cups)
把钱放入保险箱(put_money_in_safe)
拧入灯泡(light_bulb_in)
将物品放入抽屉(put_item_in_drawer)
智能体需对序列输入做出连续动作预测:三维位置(XYZ)、旋转(四元数)、抓取信号(是否夹取)。挑战评估模型对任务目标完成度、轨迹质量与精度的适应能力。
二、系统架构与模型设计 为统一处理所有任务,我们设计了统一结构的策略网络 TaskModel,其整体结构分为以下三个部分:
2.1 编码器:ActionDecoder.encoder 输入为 [B, T, D] 的观测向量序列(图像 + 语言的融合特征),经过两层全连接网络映射到维度为 embed_dim=128 的特征表示,并通过 ReLU 激活增强非线性表达能力。
2.2 时序建模模块:TemporalBlock 采用标准的 Transformer 子结构(多头注意力 + 残差 LayerNorm + 前馈网络),能够建模动作序列中时间步间的依赖关系与长期轨迹规律:
1 MultiheadAttention -> LayerNorm -> MLP -> LayerNorm
该模块允许模型识别出不同时间步之间的操作规律,如“插入-旋转-释放”等时序动作序列。
2.3 动作解码头
head_pos: 输出每一步的三维位置(XYZ)head_rot: 输出归一化四元数,表示旋转角度head_grip: 输出抓取信号,通过 sigmoid 激活
最终模型输出维度为 action_dim = 3 + 4 + 1 = 8。
三、任务感知的损失函数设计 我们在 TaskModel.compute_loss() 中为不同任务设计了特定的损失加权策略,从而提高模型在各类任务中的表现力与泛化性。
通用损失构成:
loss_pos: 所有时间步的 MSE(位置)loss_rot: 所有时间步的 Cosine 相似度损失(四元数)loss_grip: 所有时间步的 BCE(抓取信号)
任务特化策略如下:
任务名称
调整策略
stack_blocks
强调最后一步的位置稳定性 与旋转精度 ,将最后一帧位置误差加入损失,并将旋转损失权重翻倍。
place_cups
增加轨迹差值损失项,鼓励轨迹对齐;同时强调最后时刻的旋转一致性 ,增强杯口方向控制。
put_money_in_safe
加强末帧抓取状态与位置精度的监督,确保插入时精度与夹持控制。
light_bulb_in
提高位置与旋转损失权重,适配对姿态和插入精度的高要求;抓取控制也更为关键。
put_item_in_drawer
默认使用 put_money_in_safe 相似策略,注重轨迹尾部插入点与释放状态的联合优化。
四、训练与实现细节
参数
配置
Batch Size
32
Epochs
30
Optimizer
Adam
Learning Rate
1e-4
Scheduler
Cosine Annealing
Sequence Length
10
Input Dim
64(图像+语言特征)
Embed Dim
128
代码实现基于 PyTorch 框架,支持多任务训练与微调。每个任务模型独立训练并评估。
五、实验结果与分析 在官方验证平台上的评测结果如下(分数越高表示性能越优):
任务名称
得分
put_money_in_safe
292.48
stack_blocks
219.12
light_bulb_in
284.34
put_item_in_drawer
320.00
place_cups
260.35
该结果表明我们的方法在多任务适配性与精度控制方面具有良好的表现,尤其是在插入与抓取精度要求高的任务中(如 drawer, light bulb)。
六、使用工具与环境
开发语言:Python 3.10
框架库:PyTorch 2.1.0、NumPy、WandB(日志)、Matplotlib(可视化)
环境配置:CUDA 12.1,Ubuntu 22.04
ai工具:ChatGPT-4o
七、挑战与展望 我们观察到如下挑战与优化方向:
多任务共享结构 :虽然当前模型能适应多任务,但可能存在参数干扰问题。未来考虑引入任务提示向量(Task Prompt)进行条件控制。语言与图像融合方式 :当前仅使用预融合输入,未来可尝试引入 Cross-Attention 机制实现更强的模态融合。动作输出结构优化 :不同任务在输出精度要求差异大,可设计更细粒度的输出头或使用分层结构优化不同粒度的预测项。针对不同任务的特性进一步优化。
八、 部分代码展示 关键代码:
1. 模型主干设计(BasePolicy) 这是所有任务共享的基本网络结构,使用了 ResNet18 提取视觉特征,并用 TransformerEncoder 编码语言。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class BasePolicy (nn.Module):def __init__ (self ):super ().__init__()True )self .vision_encoder = nn.Sequential(*list (resnet.children())[:-1 ])512 , nhead=8 )self .lang_encoder = nn.TransformerEncoder(encoder_layer, num_layers=2 )self .cross_modal = nn.MultiheadAttention(embed_dim=512 , num_heads=8 , batch_first=True )self .fc_out = nn.Sequential(1024 , 256 ), nn.ReLU(),256 , 128 ), nn.ReLU(),128 , 7 )self .grip_cls = nn.Sequential(1024 , 64 ), nn.ReLU(),64 , 2 )
2. 跨模态编码(视觉 + 语言) 视觉特征和语言特征交叉融合,通过 Multi-Head Attention 得到联合特征。
1 2 3 4 5 6 7 8 def encode_inputs (self, obs, instr ):self .vision_encoder(obs).view(B, C_view * Two, -1 ).mean(dim=1 )1 , 0 , 2 )self .lang_encoder(instr).permute(1 , 0 , 2 )self .cross_modal(vision_feat.unsqueeze(1 ), lang_feat_seq, lang_feat_seq)return vision_feat, lang_feat_att.squeeze(1 )
3. loss函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def multi_loss (pred, target, task=None , epoch=0 ):3 ], target[:, :3 ])min (1.0 , epoch / 20.0 )3 :7 ], target[:, 3 :7 ]) * rot_weight7 :].long().squeeze(1 )1 - pred[:, 7 :], pred[:, 7 :]], dim=1 ), grip_target)if task == 'stack_blocks' :2.0 elif task == 'put_money_in_safe' :1.5 elif task == 'light_bulb_in' :1.3 1.2 return pos_loss + rot_loss + 0.1 * grip_loss