AI_lab6(未整理,乱七八糟)
深度强化学习
传统的RL算法有个很大的问题在于它是一种表格方法,就是根据过去出现过的状态,统计和迭代Q值。
- 基于表格的方法局限性很大:(对未知的泛化能力弱)
- 一方面适用的状态和动作空间非常小,对于图像和高维度离散状态、连续域状态无法直接适用;
- 另一方面对于一个状态从未出现过,这些算法是无法处理的
DQN算法:
将Q-learning和深度神经网络结合(直接结合是naive DQN),并引入两个机制经验回放和目标网络。
经验回放(replay buffer):将智能体探索环境得到的数据储存起来,然后随机采样小批次样本更新深度神经网络的参数
- 可以消除数据之间的时间相关性=>数据接近于独立同分布
- 数据利用率高
目标网络:额外引入一个目标网络,此目标网络不更新梯度,每隔一段时间将Q网络的参数赋值给此目标网络。
引入原因:
- 深度神经网络作为有监督学习模型,要求监督数据标签是稳定的
- Q-Learning算法使用下一时刻的Q值和奖励值作为监督信号,由于每次神经网络更新后,Q值会变化,导致Q-Learning算法的监督信号不稳定。
优点:
- 一定程度降低了当前Q值和目标Q值的相关性。
- 在一段时间里目标网络的Q值是保持不变的,提高了算法稳定性。(过一段时间后才会更新)


- 第1行:算法名称—-带有经验回放的DQN算法。
- 第2行:初始化经验池以及容量N。
- 第3行:以一个随机权重,初始化动作-价值函数 Q。
- 第4行:开始一个一级循环(就是一个大循环),循环的条件是回合数,满足回合方可跳出。
- 第5行:初始化回合的第一个状态s1 ,预处理得到状态对应的特征输入。
- 第6行:从该回合的第一步出发,进行循环T步才结束。
- 第7行:用随机概率epsilon选择一个动作at(在代码中这里是比较变量和epsilon大小)。
- 第8行:否则,选择上一次的最大Q值对应的at作为本次动作。(注意,这里选最大动作时用到的值函数网络与逼近值函数所用的网络是一个网络,在代码中就是用的同一个类来实例化两个网络)上边的这两行,其实就是执行贪婪策略。
- 第9行:在仿真环境中执行动作at,并获取奖励rt和下一个状态xt+1(下一帧图像信息xt+1)。
- 第10行:更新环境状态,和权重参数等。
- 第11行:在经验池中存储刚才的一组数据。
- 第12行:从经验池中取样一个batch(这个批量的大小是可以自己设置的)
- 第13行:进行判断,如果还没到达最终条件,根据迭代公式计算Q值;如果到达,以最后一次奖励作为本次的Q-T网络目标值。
- 第14行:针对Q-Target(目标函数)和Q值函数之差的Loss,运用梯度下降策略去求解最优。一般是每隔C步更新一次TD目标网络权值。
- 第15行:完成一个回合之后跳出循环。
- 第16行:完成所有回合之后跳出循环。
强化学习分享(一) DQN算法原理及实现_dqn代码-CSDN博客
Q-Learning
Q学习算法是强化学习中的一种,更准确的说,是一种关于策略的选择方式。
实际上,我们可以发现,强化学习的核心和训练目标就是选择一个合适的策略Policy,使得在每个epoch结束时得到的reward之和最大。
Q学习的思想是:Q(S, A) = 在状态S下,采取动作A后,未来将得到的奖励Reward值之和。
Q值更新的方法:
- 状态和行为的组合是有限的,采用S-A表格记录
$Q^{new}(s_t,a_t)\gets(1-\alpha)·Q(s_t,a_t)+\alpha·(r+\gamma)·max_aQ(s_{t+1},a))$ - 无限的,就将深度学习与Q-learning结合。用神经网络来代替这张Q表格。
DQN: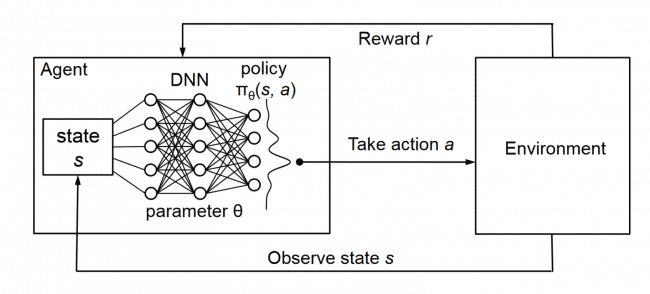
强化学习 (DQN) 教程 — PyTorch 教程 2.7.0+cu126 文档 - PyTorch 深度学习库
实验任务
CartPole任务
- 在CartPole环境中实现DQN算法。
要求: - 在给定的代码框架下补充代码。
- 最终的reward至少收敛至180.0(注意:这里的reward指一局游戏的奖励值之和)。
- 评分标准:以算法收敛的reward大小、收敛所需的样本数量给分。 reward越高(最大是200)、收敛所需样本数量越少,分数越高。
相关介绍:
Cart Pole - Gym Documentation
| Num | Shape |
|---|---|
| Action Space | Discrete(2) |
| Observation Shape | (4,) |
| Observation High | [4.8 inf 0.42 inf] |
| Observation Low | [-4.8 -inf -0.42 -inf] |
| Import | gym.make("CartPole-v1") |
action space:
The action is a ndarray with shape (1,) which can take values {0, 1} indicating the direction of the fixed force the cart is pushed with.
只有两个方向可以移动,左和右
| Num | Action |
|---|---|
| 0 | Push cart to the left |
| 1 | Push cart to the right |
| 注: 由施加的力减少或增加的速度不是固定的,它取决于角度 杆子指向。杆子的重心会改变将推车移动到其下方所需的能量 |
observation space:
The observation is a ndarray with shape (4,) with the values corresponding to the following positions and velocities:
| Num | Observation | Min | Max |
|---|---|---|---|
| 0 | Cart Position | -4.8 | 4.8 |
| 1 | Cart Velocity | -Inf | Inf |
| 2 | Pole Angle | ~ -0.418 rad (-24°) | ~ 0.418 rad (24°) |
| 3 | Pole Angular Velocity | -Inf | Inf |
| 注意:虽然上面的范围表示每个元素的观测空间的可能值, 它不反映未终止剧集中状态空间的允许值。特别: |
The cart x-position (index 0) can be take values between
(-4.8, 4.8), but the episode terminates if the cart leaves the(-2.4, 2.4)range.The pole angle can be observed between
(-.418, .418)radians (or ±24°), but the episode terminates if the pole angle is not in the range(-.2095, .2095)(or ±12°)
奖励reward:
由于目标是为了尽可能长时间保持小杆垂直,所以只要没有掉落的每一步都应该累积奖励+1,
开始状态:
All observations are assigned a uniformly random value in (-0.05, 0.05)
Episode End
The episode ends if any one of the following occurs:
- Termination: Pole Angle is greater than ±12°
- Termination: Cart Position is greater than ±2.4 (center of the cart reaches the edge of the display)
- Truncation: Episode length is greater than 500 (200 for v0)
.load_state_dict()
- 把参数字典加载到另一个(结构相同的)网络。
- 例子:
self.target_q_net.load_state_dict(...)把参数加载到目标网络。
summarywrite :它允许你在训练过程中记录各种指标(如 reward、loss、accuracy、参数分布等),然后用 TensorBoard 直观地可视化这些数据。
gym.Env.reset(_self_, _*_, _seed: int | None = None_, _options: dict | None = None_) → Tuple[ObsType, dict]
ddl:6.2
实验六
实验过程
由于之前学了如何实现CNN,我们先来实现QNet
对比卷积层数量和隐藏层大小带来的差异:
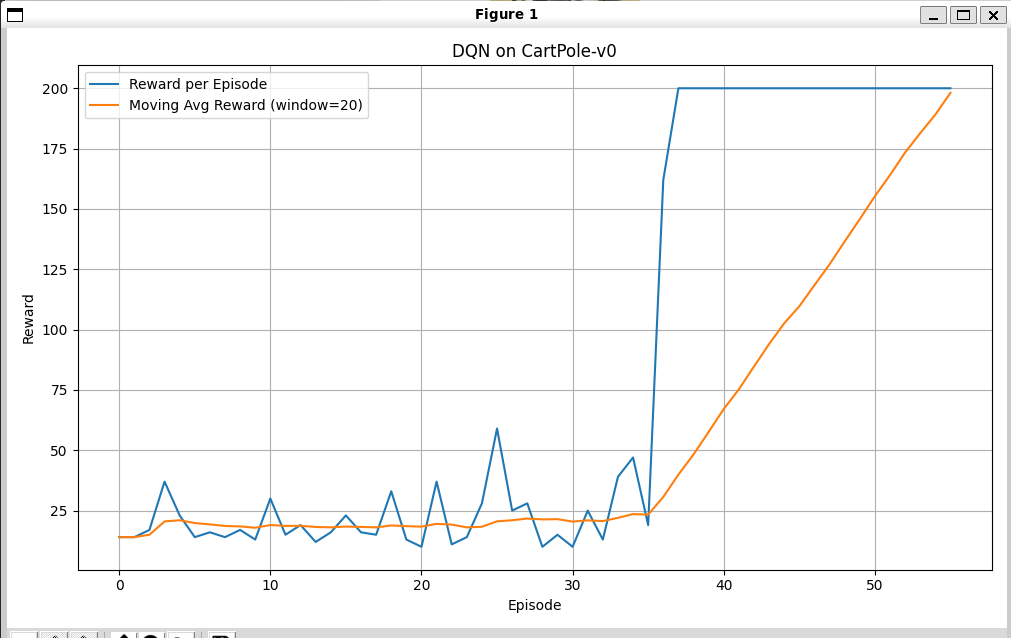
只有三层(输入+隐藏+输出):
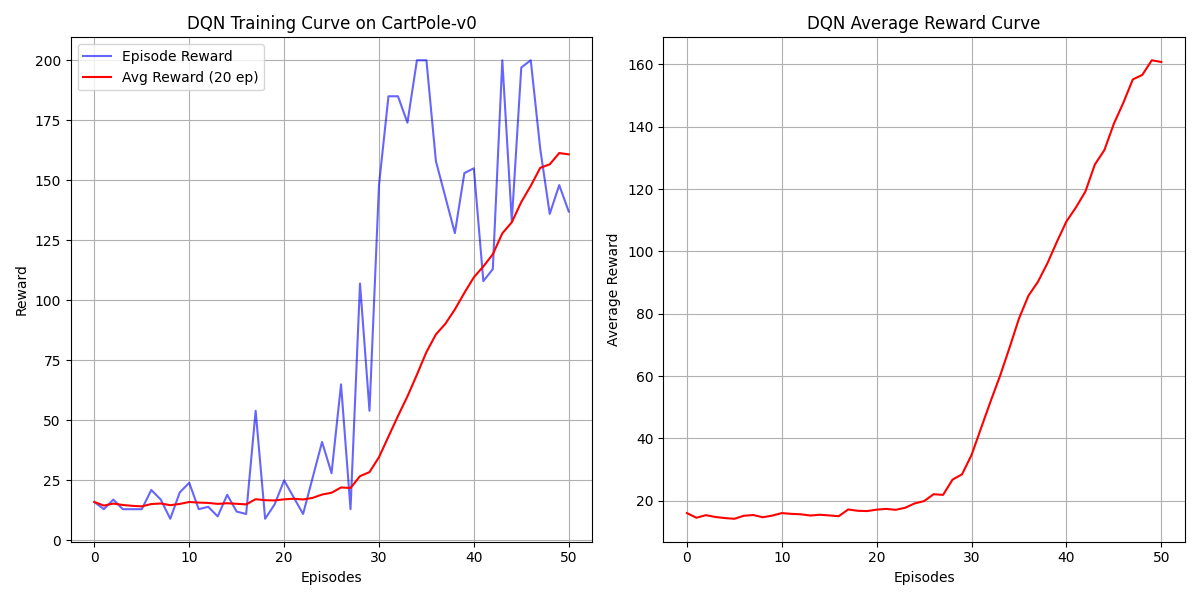
需要78轮才能收敛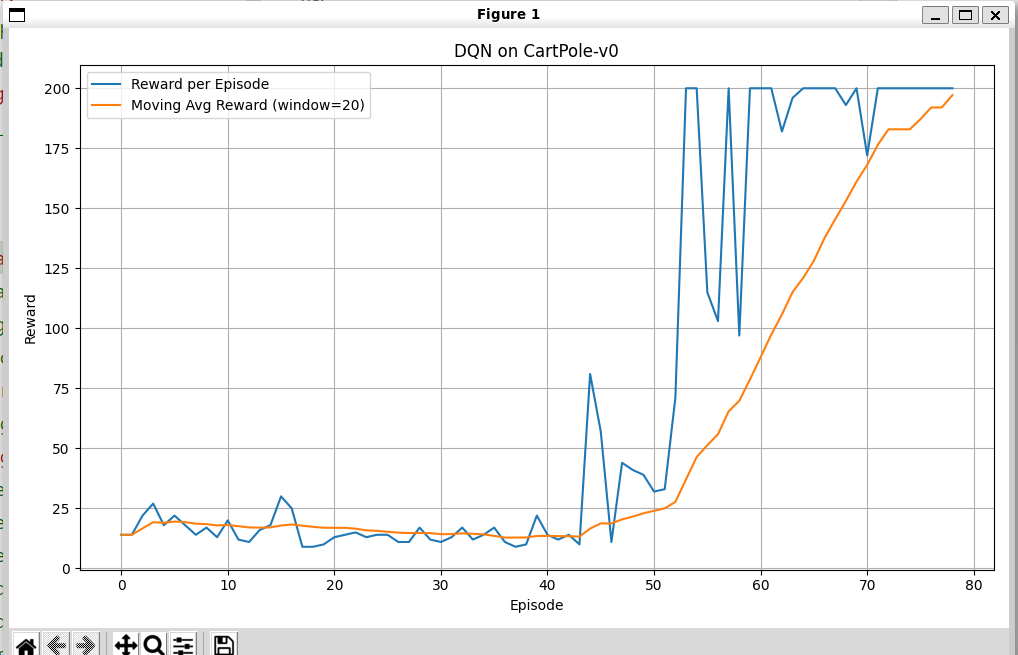
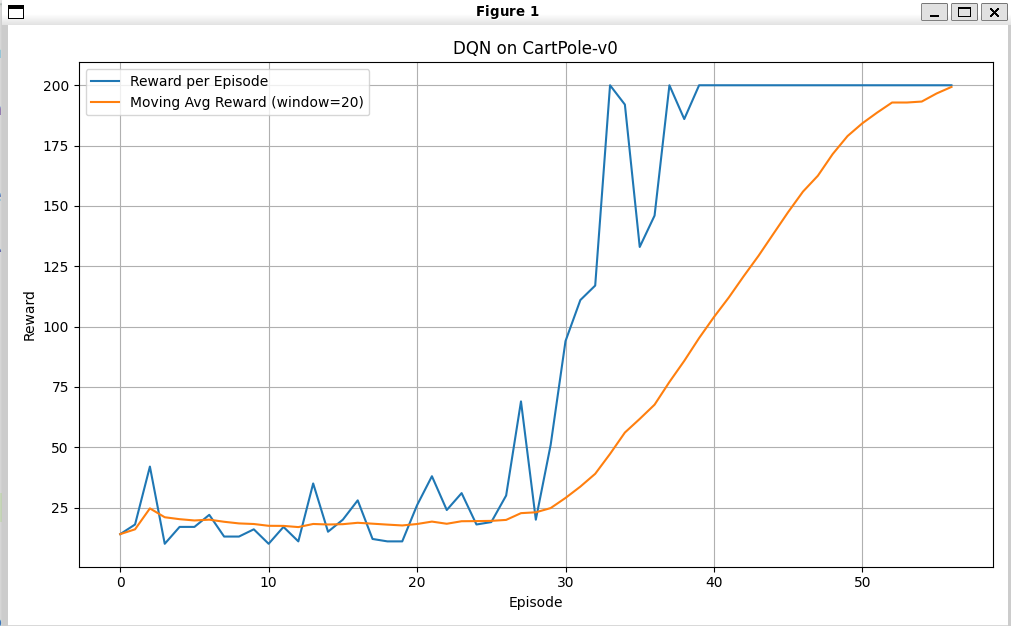
增加层数,同时设计一个纺锤形的网络:
可以在55轮就收敛: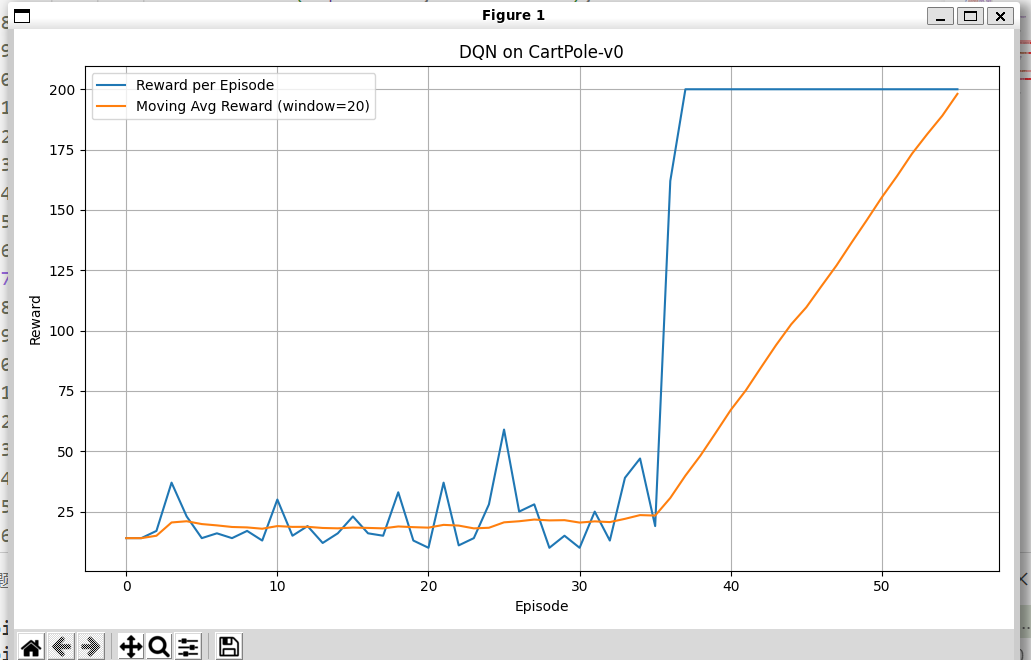
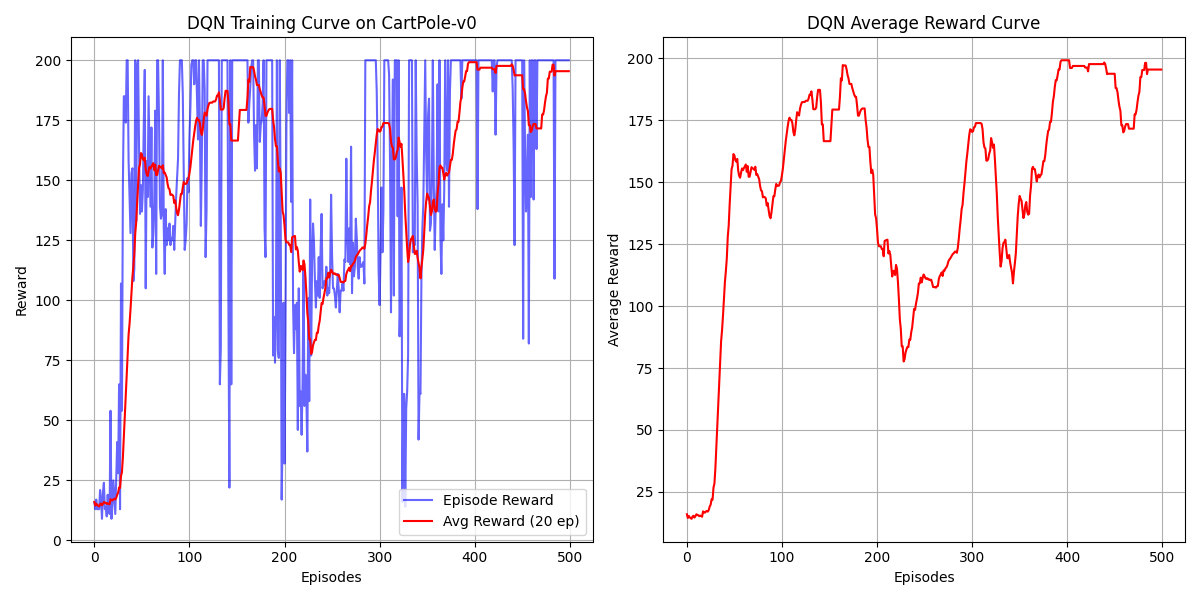
如果只增加了层数,但是没有设计纺锤形的网络:
效果反而差了很多:
在203轮才收敛!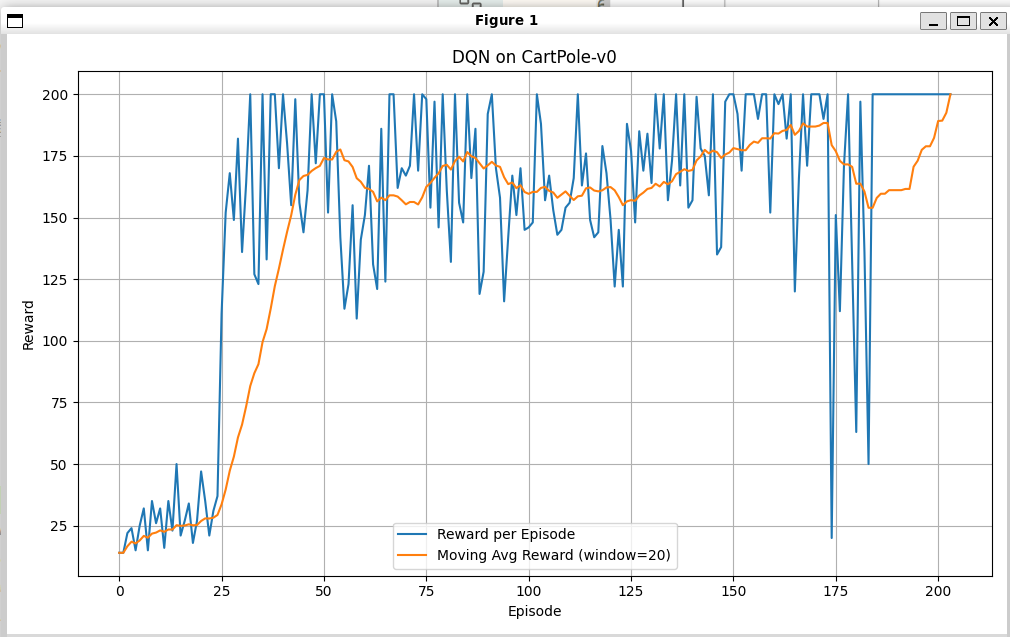
然后我们实现经验回放池:
经验回放的目的是消除样本之间的时间相关性
- 初始化函数用于初始化一个有限容量的缓冲区
- len()用于返回经验回放池的大小
- push()用于将新的样本推入池
- sample()用于随机地获取一批小样本
- clean()用于清理回放池
1 | |
训练过程:
使用的是最简单的DQN模型
微调了参数:hidden_size=256
v1.1版本
v2版本:
1 | |
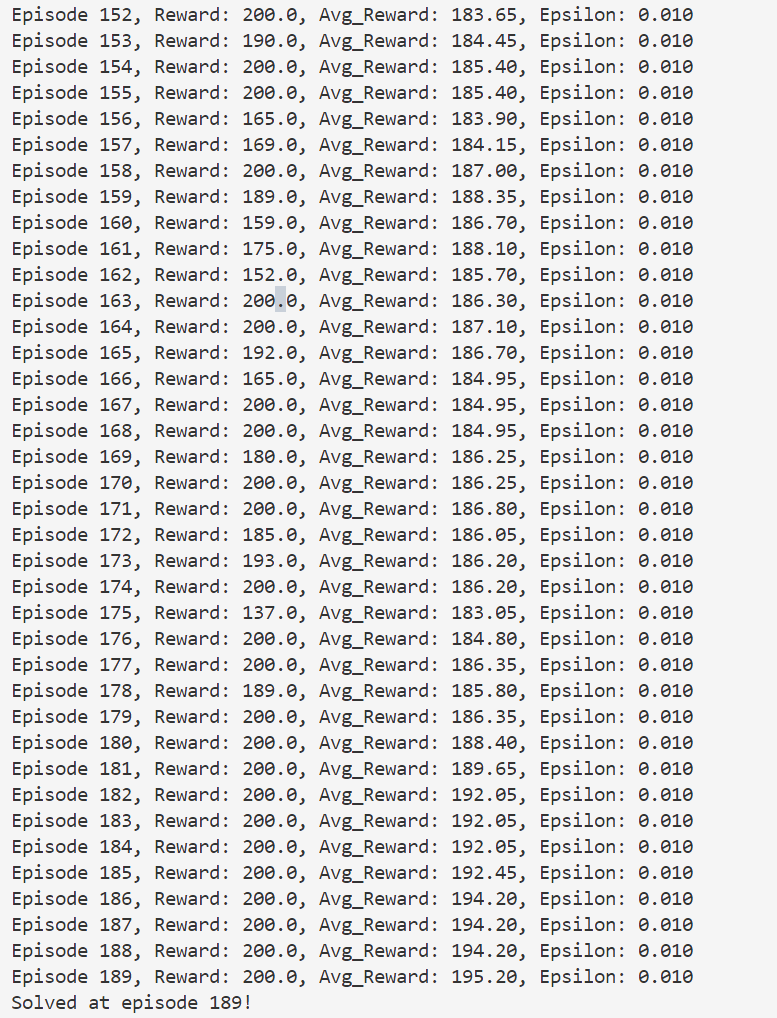
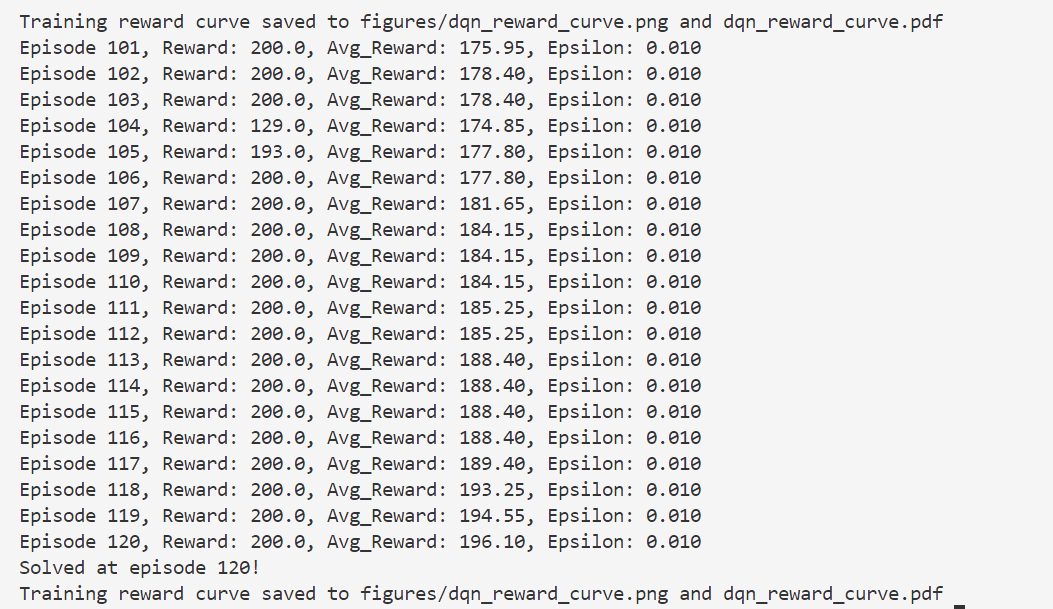
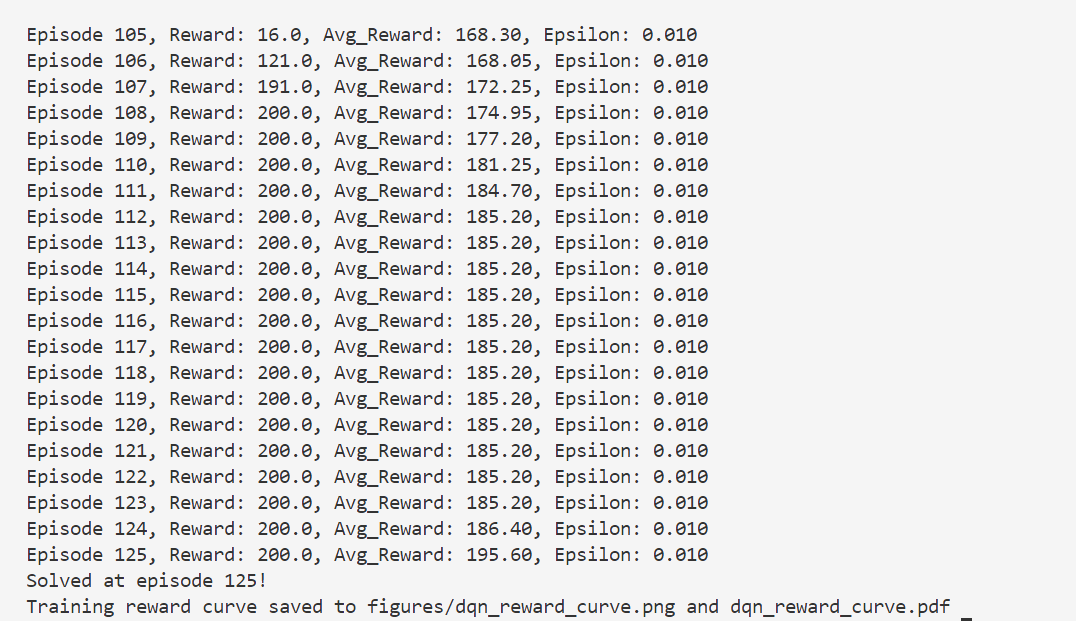
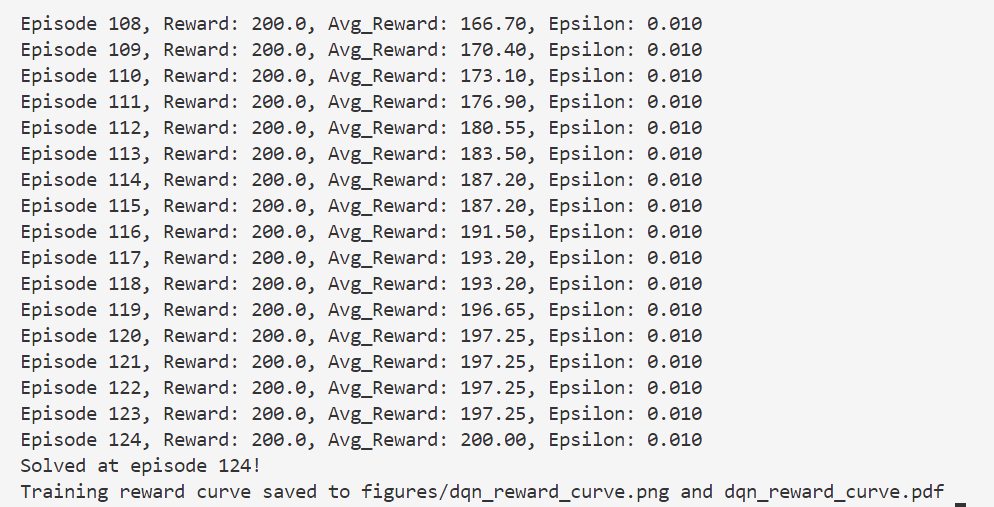
还是会出现过估计的问题。
v3:尝试引入Double DQN
效果好很多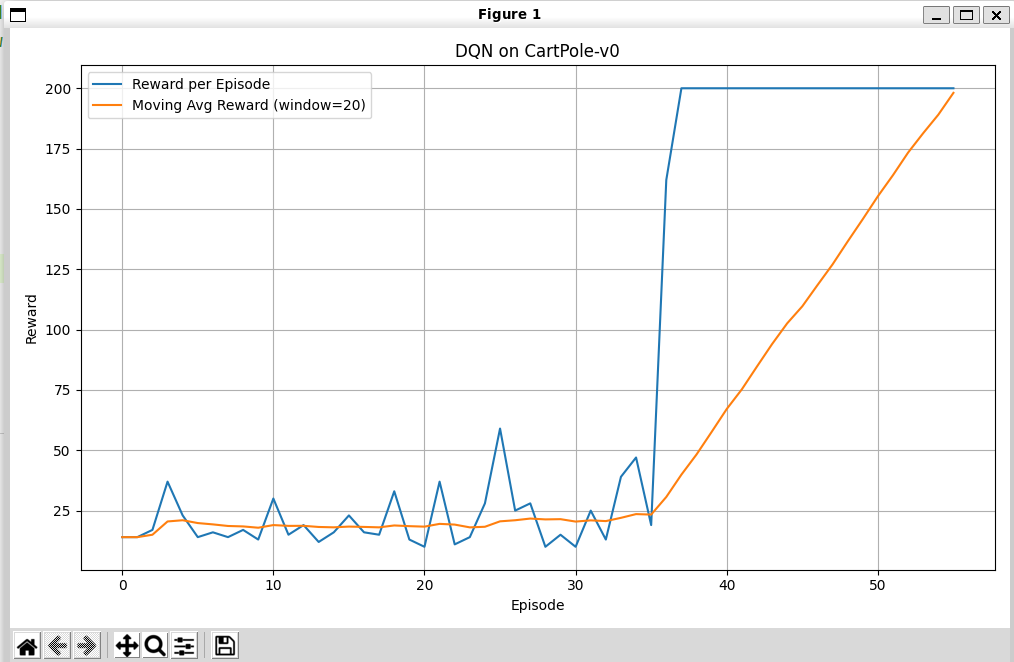

我参考教学讲义里的QNetwork类定义,写的:
1 | |
同时我在之前实验过程中学习到纺锤体的网络格式会有比较好的效果,所以我做出了一些改变:在中间使用 2*hidden_size 作为隐藏层的大小
v3版本未进行调参的运行情况:
- 效果很差,一点也不稳定,也不收敛(怀疑是因为每次采样的效果差劲)
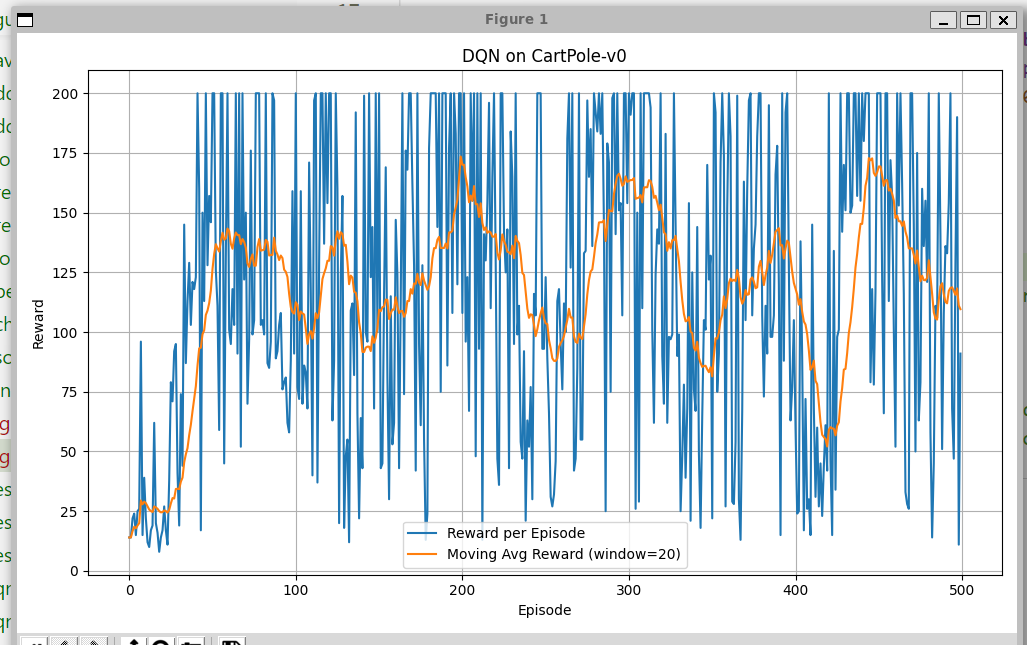
进行调参: - 仅仅调节了隐藏层大小(改为hidden_size=64,效果也很一般)几百代都不收敛,直接中断了。
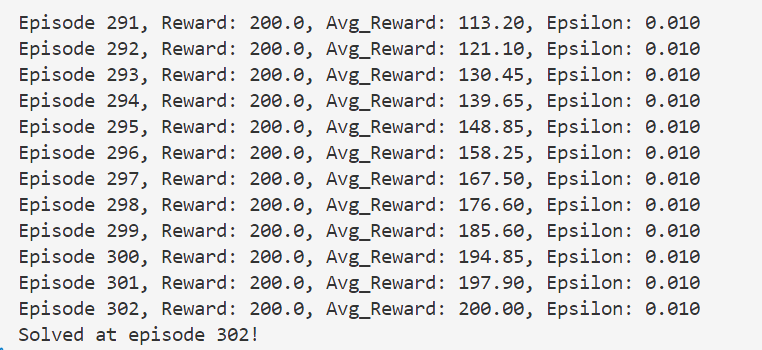
- 在修改了learning rate=1e-3和hidden_size=64之后,效果出奇的好
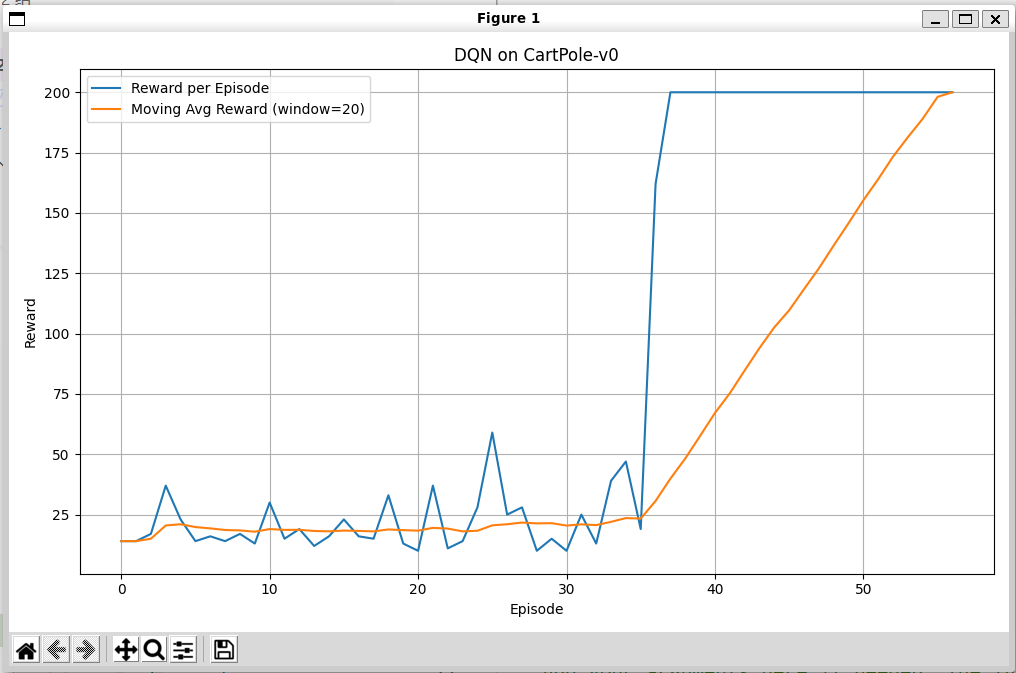
- 单独修改lr=1e-3效果也是一般,在三百多代才能收敛。
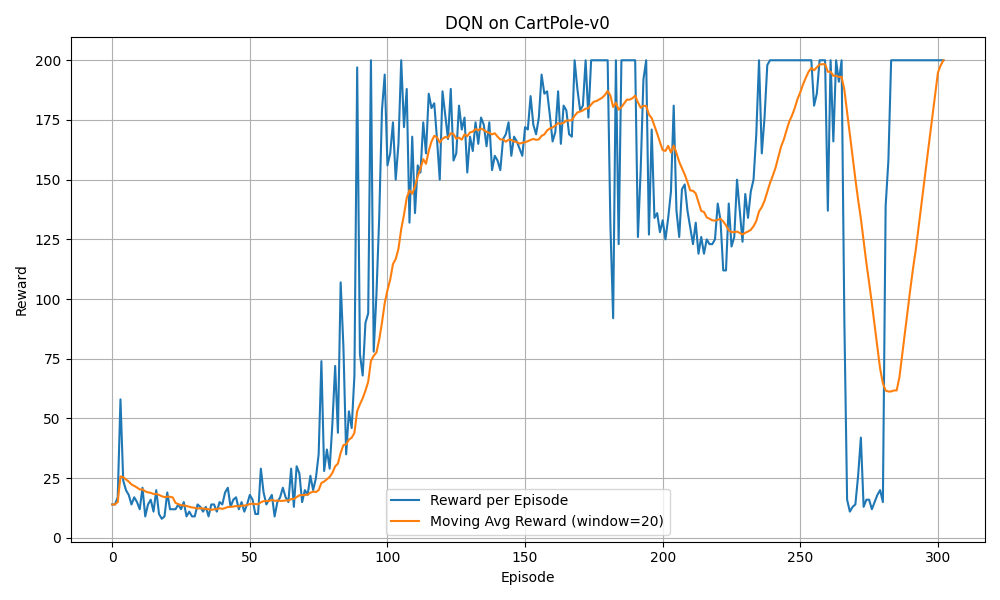
曲线也是比较波折的,但是最后能够多代稳定在200 - 调整lr=1e-4,hidden_size=64效果也是一般,需要270代左右才能收敛
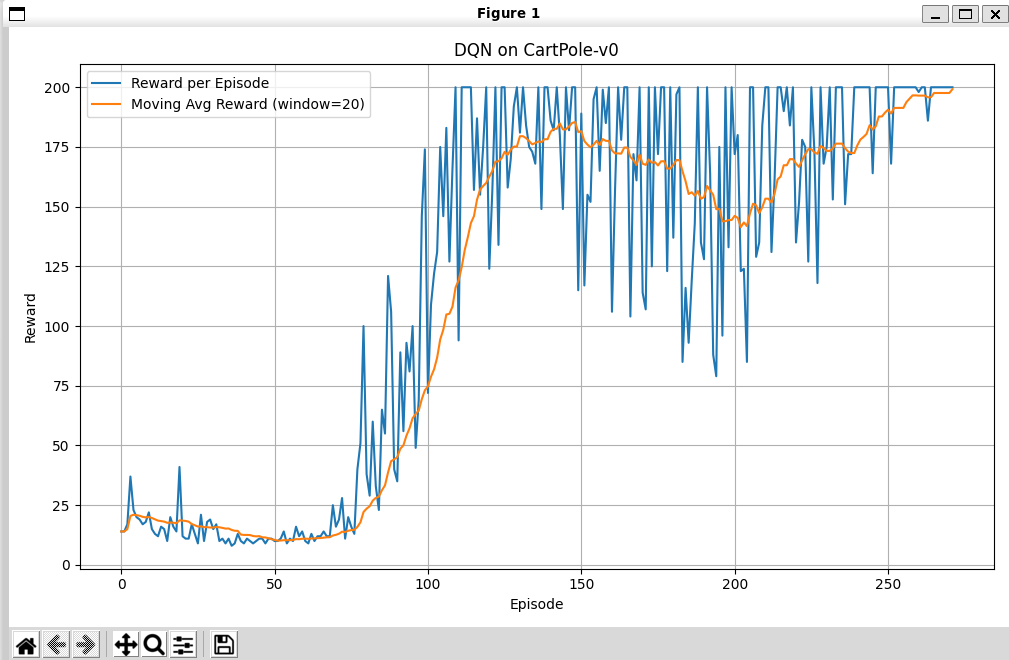
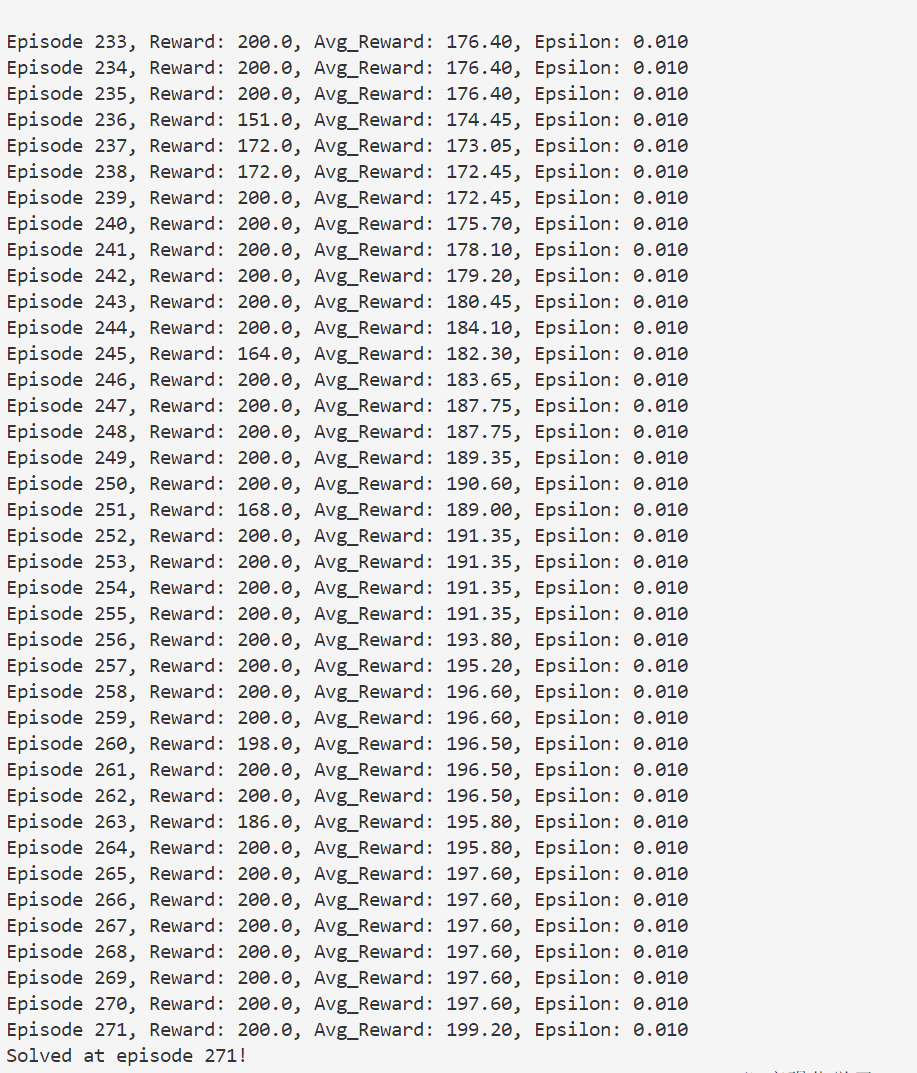
- 同时我还加载了batch_size=32,但是好像没什么区别
我修改了一下main.py,使得能正确使用dqn策略:
- 即进行判断我们选择的算法是DQN算法还是PG算法
1 | |
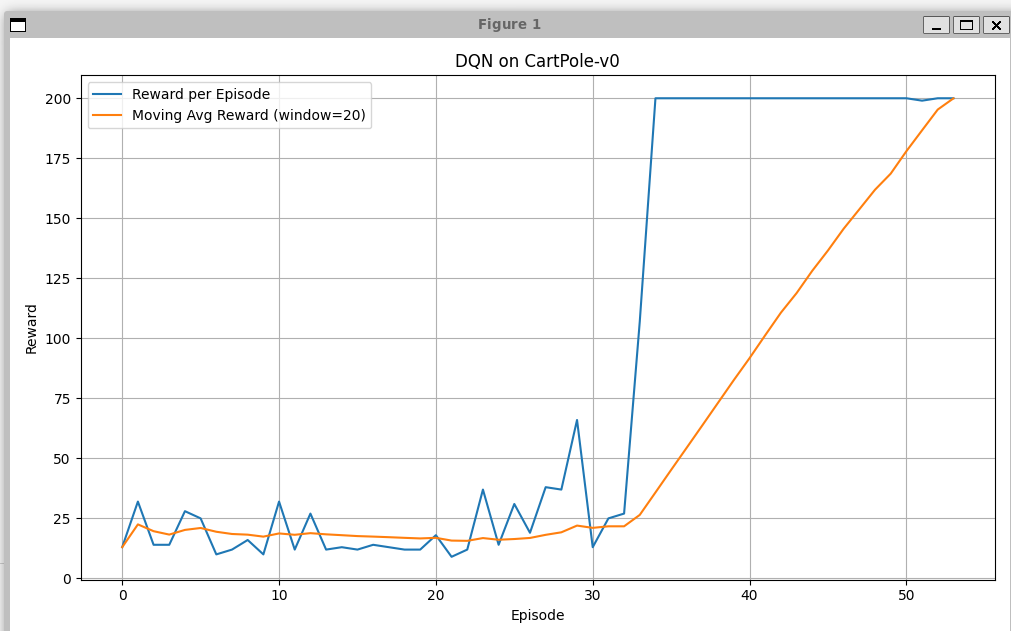
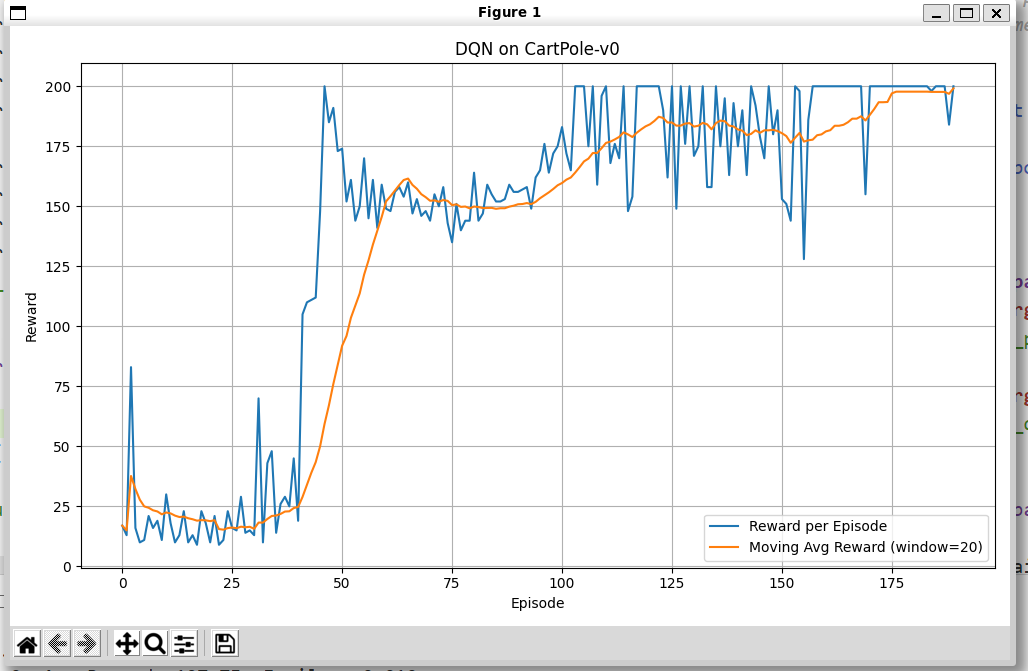
同时由于我们没有用到seed,可能效果并不稳定,所以我们在运行前还有run函数之前加上seed设置,这样子就能保证结果可以复现了。
还发现需要在gym环境设置的地方添加seed设置。