OS_lab9
Project1 malloc/free的实现
方案二:参考实现
- 参考、复现、测试并详细分析以下实现思路和代码(70分)。
- 加分项(30分):下面的代码没有做线程/进程同步和互斥处理,因此是线程不安全的。同学们可以加入进行同步互斥的代码,以保证动态内存分配时的线程安全。
动态内存分配机制包含内存分配和内存释放
lab7以“页”为粒度来进行动态内存分配
现在我们希望通过malloc/free来实现以字节为粒度进行动态内存分配
一个任意长度的内存分配单元是不好管理的。所以虽然我们实现以字节为粒度的动态分配,但我们分配的内存单元是固定的,是一些固定长度($2^N$ )
要分配大小为size个字节的内存时,找到合适的N:
- $2^{N−1}<size≤2^N$
也就是从小到大搜索,找到第一个恰好不小于size的arena。找到这样一个arena后,我们便返回arena的起始地址作为分配的结果
如果没有arena能包含size个字节时,我们分配连续的M个页,同样返回起始地址: - $(M−1)×4096<size≤M×4096$
首先需要定义arena的类型。
1 | |
由于我们是基于页内存分配来分配出arena,因此我们要做的事将页划分为一个个arena。
为了方便管理,同一个页中划分出来的arena的大小相同。然后在页的开头保存一些元信息,其中包含可分配的arena的数量和大小(或者说arena的类型)等。
![[file-20250611145140978.png]]
留出保存元信息的空间大小,剩下的才是可以划分的区域:
- $4096-sizeof(Arena)$
然后进行划分,并返回第一个arena的起始地址,剩余的arena被放入一个双向链表中,作为空闲的arena。 - 这个链表可以放置到每一个空闲的arena中,就无需开辟新空间了。
![[file-20250611145452529.png]]
空闲的arena链表:
![[file-20250611145507111.png]]
然后每一种arena都会有一条这样子的链表:
![[file-20250611145528760.png]]
复现
先定义arena.h文件,存放相关数据结构
1 | |
在list.h中添加空闲链表结构
1 | |
将字节分配管理器放在memory.h中
1 | |
然后在memory.cpp中定义ByteMemoryManager的相关方法
运行结果:
![[file-20250611175039508.png]]
发现只有用户线程中是正确的按照字节来分配,但是内核空间的分配依然是按页的。需要查找一下问题。
经过检查发现,是忘记在extern "C" void setup_kernel() 里添加 kernelByteMemoryManager.initialize();初始化!
修正过后:
![[1749866458182.png]]
然后让我们修改一下测试程序,尝试一下其他的分配块
![[file-20250614100303932.png]]
这里由于分配的是不同的arena,所以都是从x00开始分配。
![[file-20250614100821832.png]]
![[file-20250614101544750.png]]我们再测试一下对同一种arena来分配:
![[file-20250614102217285.png]]
测试结果如下:
![[img/file-20250614102235104.png]]
结果是符合的。
然后我们调用一下free来测试一下是否正确实现。
运行结果:
![[img/file-20250618162455763.png]]
从图中可以看到,不管是在内核态还是在用户态,都可以正常释放,p4就会直接占据第一个空闲的arena。
实现同步互斥
加入进行同步互斥的代码,以保证动态内存分配时的线程安全。
- 通过信号量来实现。
同步互斥未实现时出现的问题:
当我们调用malloc()为线程分配动态内存时,需要从空闲链表中获取一个arena,此时系统会执行:
- 找到一页新内存页,将其划分为多个arena
- 选取第一个arena分配给房钱的线程
- 空闲链表还没更新完,而线程被中断,调度器切换到另一个线程
- 新线程也调用malloc(),空闲链表未更新,系统认为没有空闲arena,又重新走了一遍分配流程,又返回了同一个arena地址。
- 两个线程拿到同一块地址,出现问题。
此时发生的问题就是两个线程同时访问临界区(空闲链表作为共享资源,多个线程在访问),内存的分配非原子操作。
我们可以通过设置信号量来实现,在分配arena之前P一下,然后在分配完成之后再V一下,保证同一时间只有一个线程访问或修改空闲链表。
未开启信号量测试:
代码:
- 同时我们在过程中添加时间延迟来创造线程切换的可能。
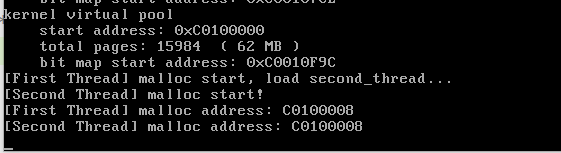
从图中可以看到,我们关闭信号量时,两个不同的arena分配到了同一块地方!
开启信号量来测试: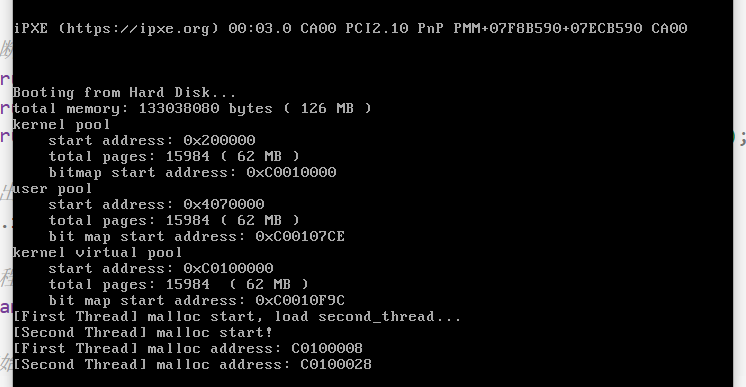 可以看见这两个线程都正确地获取了arena。
可以看见这两个线程都正确地获取了arena。