DB_Lec2
- slide
- books-chap3/4
- notes
- hw
Lecture2
| intermediate SQL
什么是SQL (Structured Query Language)?
- 读作Sequel
- SQL是一种用于管理和操作关系型数据库的标准语言
- 用于与数据库交互:查询数据、插入数据、更新数据、删除数据、创建和修改数据库结构
| 类型 | 说明 | 示例 |
|---|---|---|
| 查询语句 | 检索数据 | SELECT name FROM users; |
| 插入语句 | 插入新记录 | INSERT INTO users(name) VALUES('Alice'); |
| 更新语句 | 修改已有记录 | UPDATE users SET age = 25 WHERE name = 'Alice'; |
| 删除语句 | 删除记录 | DELETE FROM users WHERE age < 18; |
| 定义语句 | 创建/修改数据库结构(DDL) | CREATE TABLE users(id INT, name TEXT); |
| 这是声明式语言,只需要说明你需要什么数据,不需要指定如何拿到 |
MySQL和SQLite是DBMS,用于创建、管理、操作数据库
SQL is based on bags not set
bags和set的区别是bags允许有重复的键
SQL数据定义
SQL基本类型:

基本模式定义
使用 create table 命令定义SQL关系,例子:
1 | |
create table命令还指明了dept_name属性是department关系的主码
create table命令的通用形式:
r是关系名,$A_i$是关系r模式中的一个属性名,$D_i$是属性$A_i$的域,即$D_i$制定了$A_i$的类型以及可选的约束,用于限制所允许的$A_i$取指的集合
主要使用的完整性约束:
- primary key:声明表述属性构成关系的主码。主码属性必须非空且唯一——没有一个元组在主码属性上取空值,关系中也没有两个元组在所有主码属性上取指相同。
- foreign key:声明表示关系中任意元组在属性上的取指必须对应于关系s中某元组在主码属性上的取值
- not null:表明属性上不允许空值

SQL查询
查询:基本结构由三个子句构成–select、from、where
单关系查询
e.g:
1 | |
去掉重复的
1 | |
显式指明保留所有
1 | |
同时,select子句还可以含有+、-、* 、/ 运算符的算数表达式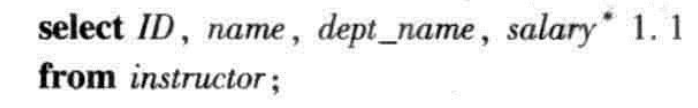
where 子句允许我们只选出那些在from子句的结果关系中满足特定谓词的元组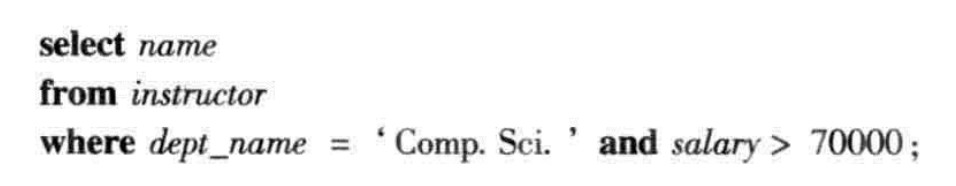
多关系查询
例子:
总述:

自然连接:

其中每个$E_i$可以是单个关系或一个包含自然连接的表达式
更名:as
字符串运算:
例子:
1 | |
属性说明:*可以用在select子句中表示所有的属性
显式次序,order by
LIMIT < count > [offset]
用于限制返回元组的数量
LIMIT 10 则会限制只返回前10条符合条件的记录
LIMIT 20 OFFSET 10 表示跳过前面10条记录,返回接下来的20条
集合运算
聚集函数:以值的一个集合为输入、返回单个值的函数。
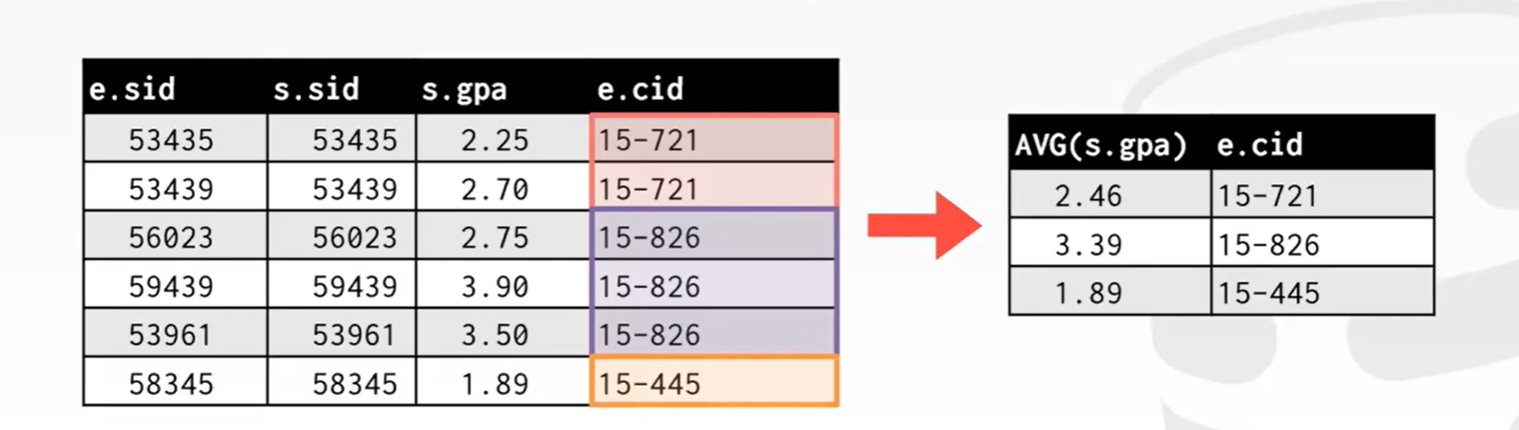
group by: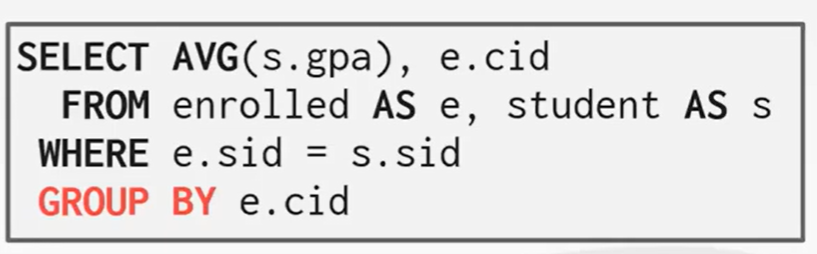
中级SQL
连接表达式
连接就是将一个或多个表的列合并起来,并产生一个新的表。
连接条件:
- 自然连接–join…using子句
- 自然连接(Natural Join) 是 SQL 中的一种连接方式,它会自动根据两个表中所有同名且类型相同的列来进行连接,不需要手动指定连接条件
- on条件允许在参与连接的关系上设置通用的谓词,出现在连接表达式的末尾
例子:
1 | |
on条件表明:如果一个来自student的元组和一个来自takes的元组在ID上的取值相同,那么他们是匹配的
1 | |
等价于:
1 | |
on条件可以表示任何SQL谓词,从而使用on条件的连接表达式就可以表示比自然连接更为丰富的连接条件
外连接
左外连接:只保留出现在左外连接运算后之前(左边)的关系中的元组
右外连接:只保留出现在右外连接运算后之后(右边边)的关系中的元组
全外链接:保留出现在两个关系中的元组
内连接只返回“两个表中都匹配的”数据。
外连接则会返回至少在一个表中存在的数据,即:
➤ 先做内连接找出匹配的行,
➤ 然后保留“未匹配上的一侧表的行”,并用NULL填充缺失部分。
| 类型 | 说明 | 典型用途 |
|---|---|---|
| LEFT JOIN | 保留左表所有数据,右表匹配或为 NULL | 主表为左侧,比如“所有学生” |
| RIGHT JOIN | 保留右表所有数据,左表匹配或为 NULL | 主表为右侧,比如“所有工资” |
| FULL OUTER JOIN | 保留两边所有数据,不匹配填 NULL | 汇总所有记录 |
内连接:inner join
- join子句中没有使用outer前缀,默认是内连接
视图
视图可以理解为一个虚拟表,它是基于一个或多个表的查询结果创建的
- 视图本事不存储数据,而是存储一个SQL查询语句的逻辑定义
视图=保存的SQL查询
视图定义
使用 create view 命令定义视图create view v as < query expression >
< query expression > 可以是任何合法的查询表达式,v表示视图名
1 | |
物化视图
特定数据库系统允许存储视图关系,但它们保证:如果用于定义视图的实际关系改变,视图也跟着修改,这样子的视图称为物化视图
| 项目 | 普通视图(View) | 物化视图(Materialized View) |
|---|---|---|
| 是否存储数据 | ❌ 不存储,只保存查询逻辑 | ✅ 存储查询结果(像一张表) |
| 性能 | 查询时重新执行原 SQL | 查询时读取已保存的数据,性能更高 |
| 是否自动更新 | ✅ 总是最新 | ❌ 默认不自动更新,需要手动或定时刷新 |
| 是否实时 | ✅ 实时 | ❌ 非实时,取决于刷新策略 |
视图更新
SQL视图可更新:
- from子句中只有一个数据库关系
- select子句只包含关系的属性名,不包含任何表达式、聚集或distinct声明
- 任何没有出现在select子句中的属性可以取空值
- 查询中不含有group nby或having子句
允许update、insert和delete
事务
事务由查询和(或)更新语句的序列组成
SQL标准规定当一条SQL语句被执行,就隐式地开始了一个事务
事务是数据库中的一个操作单元,由一组 SQL 语句组成,要么全部执行成功,要么全部失败回滚。
特性:
原子性、一致性、隔离性、持久性
DATE和TIME
例子:
查询今天的日期
1 | |
然后就会返回今天的日期
利用一些数据库定义的函数,可以得到某天到某天之间的日期差,等等
NESTED QUERIES 内部查询
嵌套查询就是在一个 SELECT、INSERT、UPDATE 或 DELETE 语句中,再写一个完整的 SELECT 查询,用来提供中间结果或条件。
例子:
1 | |
即,先查出上了CS101的学生编号,再查询他们的名字
Nested Query Results Expressions:
• ALL: Must satisfy expression for all rows in sub-query.
• ANY: Must satisfy expression for at least one row in sub-query.
• IN: Equivalent to =ANY(). SELECT * FROM course
• EXISTS: At least one row is returned.
| 关键词 | 作用 | 举例说明 |
|---|---|---|
ALL |
与所有子查询结果比较 | x > ALL(...):大于全部 |
ANY |
与任一子查询结果比较 | x > ANY(...):大于其中一个 |
IN |
是否出现在子查询结果中 | x IN (...) 等价于 x = ANY(...) |
EXISTS |
子查询是否返回至少一行 | 有记录就为 TRUE |
窗口函数
窗口函数时一种对一组相关记录(窗口)进行计算的函数,它不会像普通的聚合函数那样把多行变成一行,而是保留原来的行数并添加新列。
Common Table Expressions(CTE)
1 | |
高级SQL
- 学习如何通过通用程序设计语言来访问SQL
- 通过拓展SQL语言来支持程序的操作
- 数据库中执行程序语言中定义的函数
- 触发器:用于说明当特定事件发生时自动执行的操作
- 递归查询和高级聚集特性
使用程序设计语言访问数据库
原因:
- SQL没有提供通用程序设计语言那样的表达能力,不能表达所有查询要求
- 非声明性的动作都不能用SQL实现
实现:
- 动态SQL:通用程序设计语言可以通过函数或者方法来连接数据库服务器并与之交互。
- 在运行时以字符串形式构建SQL查询,提交查询,如何把结果存入程序变量中,每次一个元组
- 嵌入式SQL:嵌入式SQL语句必须在编译时全部确定,并交给预处理器
嵌入式SQL:
Homework
Overview
The first homework is to construct a set of SQL queries for analysing a dataset that will be provided to you. For this, you will look into IMDB data. This homework is an opportunity to: (1) learn basic and certain advanced SQL features, and (2) get familiar with using a full-featured DBMS, SQLite, that can be useful for you in the future.
第一个作业是构建一组 SQL 查询,用于分析将提供给您的数据集。为此,您将研究 IMDB 数据。这个家庭作业是一个机会:(1) 学习基本和某些高级 SQL 功能,以及 (2) 熟悉使用功能齐全的 DBMS SQLite,这对您将来可能很有用。
作业共包含10道题,满分100分。对于每个问题,您需要构建一个 SQL 查询,从 SQLite DBMS 获取所需的数据。完成问题可能需要大约 6-8 小时。
提交:
使用将用于每个问题的空 SQL 文件创建占位符提交文件夹:
1 | |
填写查询后,您可以通过运行以下命令来压缩文件夹:
1 | |
该标志允许您压缩 zip 文件中的所有 SQL 查询,而不提供路径信息。除非您这样做,否则评分脚本将无法正常工作。-j
指示:
设置SQLite
选择在Linux上安装SQLite3
发现现在的ubuntu linux几乎都自带了SQLite3,检查了一下,确实存在。
过了一会发现,这个是安装在python虚拟环境下的sqlite3,所以打算重新安装。成功打开sqlite3和课程提供的数据库
发现数据库中有六个表
1 | |
- 在SQLite中使用命令,创建索引
1 | |
查看每张表的结构(schema):使用命令 .schema $TABLE_NAME
比如:.schema akas 就可以看到
1 | |
检查完之后就可以开始构造SQL查询了
模板:
1 | |
Q1:q1_sample
此查询的目的是确保 您的输出格式与我们的自动评分脚本的格式完全匹配。
详:列出按字母顺序排序的所有类别名称。
答案:以下是正确的 SQL 查询和预期输出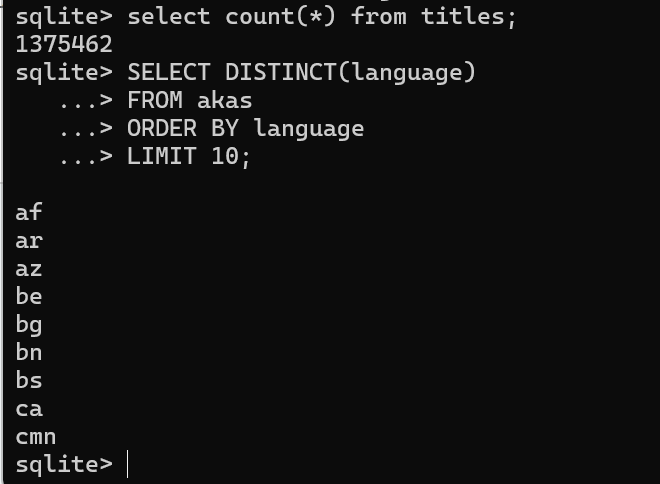
将查询的sql语句粘贴到文件中即可。
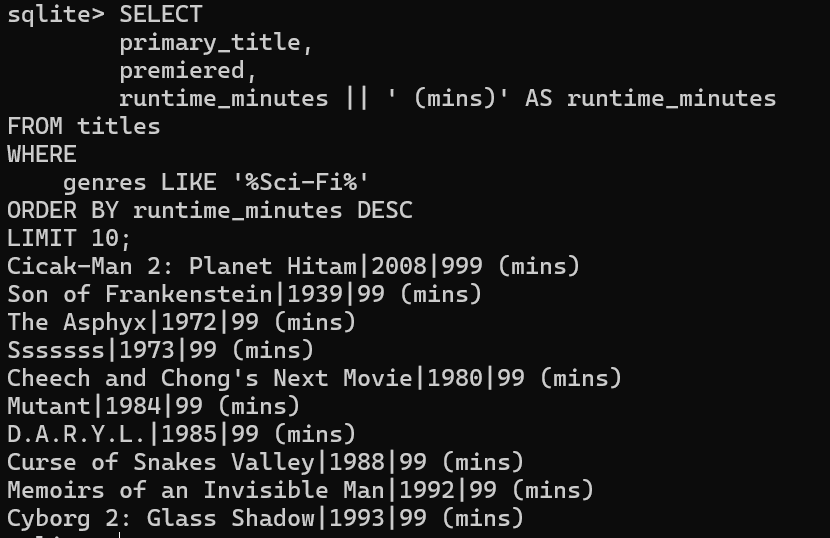
Q2 [5 分] (q2_sci_fi):
找到运行时间最长的 10 部“科幻”作品。
详:打印作品的标题、首播日期和运行时间。 列出运行时的列应以字符串 “ (mins)” 为后缀, 例如,如果 runtime_mins 值为 ‘12’,则应输出 12 (mins) 。Note a work is Sci-Fi even if it is categorized in multiple genres, as long as Sci-Fi is one of the genres.
您的第一行应如下所示:Cicak-Man 2: Planet Hitam|2008|999 (mins)
1 | |
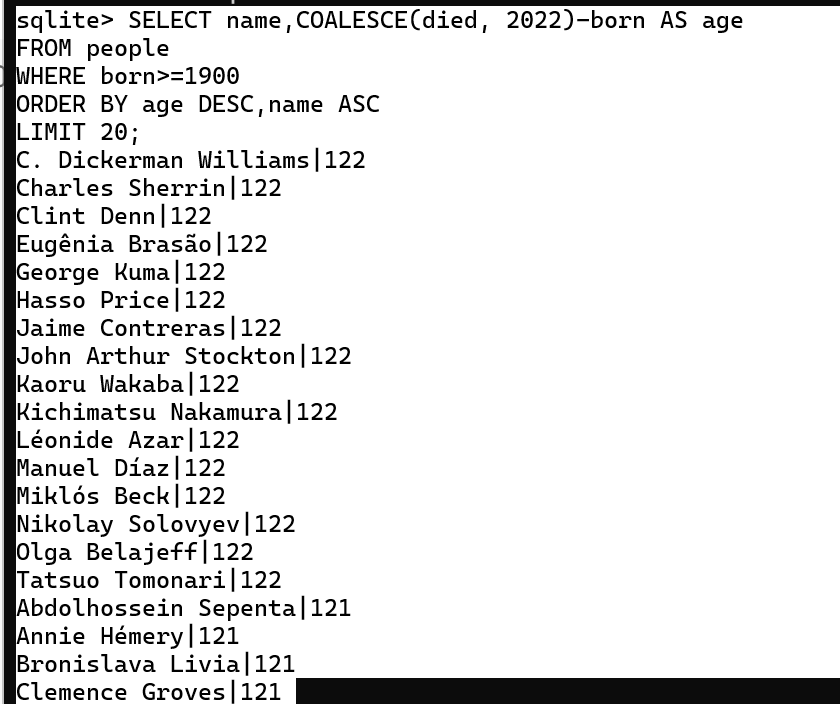
Q3 [5 分] (q3_oldest_people):
确定数据集中出生于 1900 年或之后的最年长的人。 您应该假设一个没有已知死亡年份的人还活着。
详:打印每个人的姓名和年龄。人们应该 按年龄的复合值排序,其次是他们的名字 按字母顺序排列。返回前 20 个结果。
输出的格式应为:NAME|AGE
1 | |
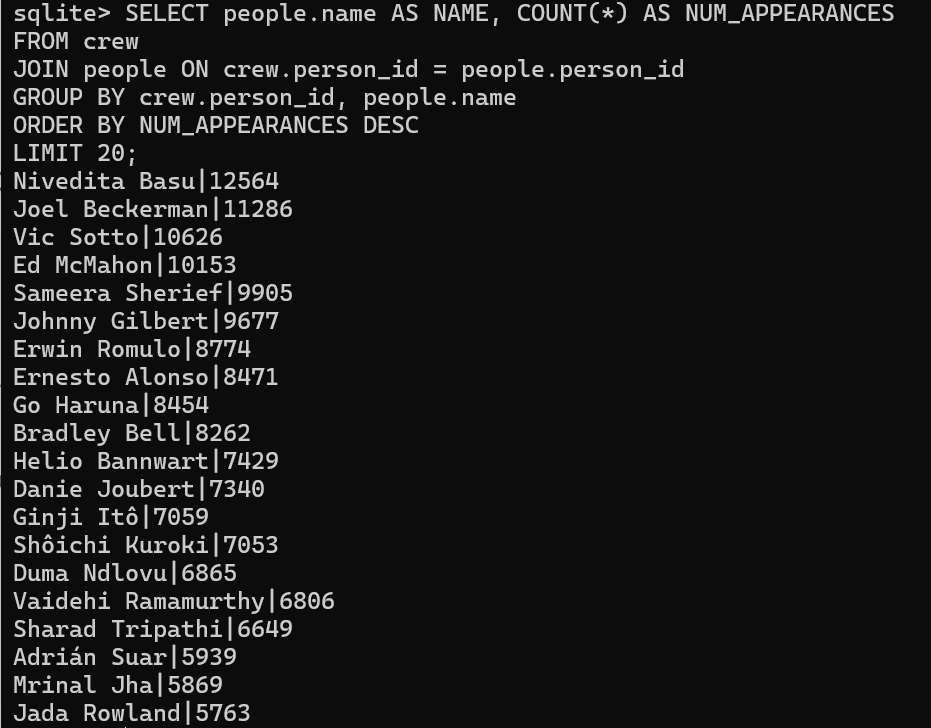
Q4 [10 分] (q4_crew_appears_most):
查找最常以船员身份出现的人。
详:打印20人的姓名和出场次数 最多的船员出场次数按出场次数排序 以下降的方式。
您的输出应如下所示:NAME|NUM_APPEARANCES
1 | |
1 | |
问题 5 [10 分] (q5_decade_ratings):
计算每十年内容评级的有趣统计数据。
**详:**获取平均评分(四舍五入到小数点后两位)、最高评分、 最小评级,以及每个十年的发布次数。排除尚未首映(即首映的位置 NULL )。打印相关 decade 以更奇特的格式构建一个如下所示的字符串:1990s .按降序的平均评分对几十年进行排序 时尚,其次是十年,上升,断绝关系。
输出的格式应为:DECADE|AVG_RATING|TOP_RATING|MIN_RATING|NUM_RELEASES
1 | |
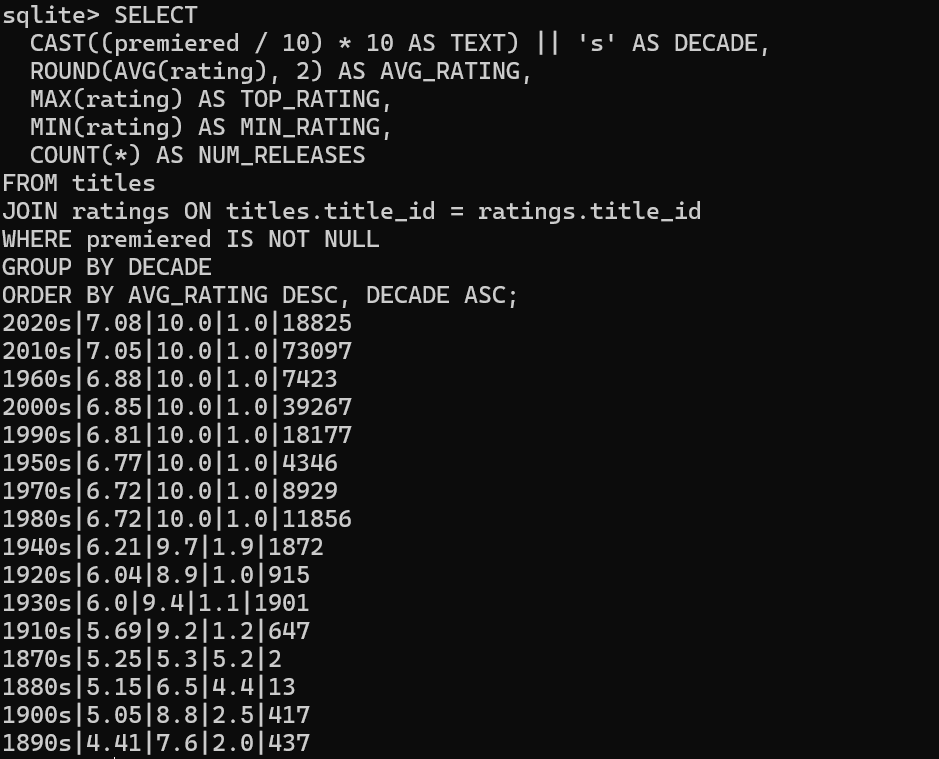
COUNT(*):统计符合条件的所有行数,无论这些行中有没有NULL值
FROM只写了titles是因为,我通过自然连接,把ratings的信息给并过来了,他们合成一个表,所以就只用写titles
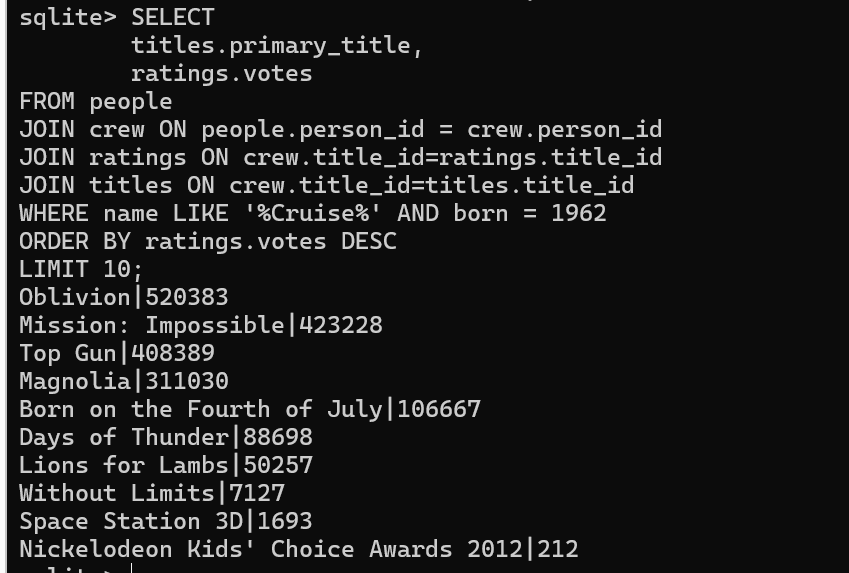
问题 6 [10 分] (q6_cruiseing_altitude):
找出由出生于 1962 年、名字中包含 “Cruise” 的人参与的、最受欢迎(投票数最多)的作品。
**详:**获得得票最多且剧组中有一人的作品 他们的名字中带有“Cruise”,出生于 1962 年。返回 工作和投票数,并仅按顺序列出前 10 名结果 从多到最少的选票。确保输出的格式如下:Top Gun|408389
查询逻辑:
- 从people表中找出所有名字里含Cruise且出生于1962年的人
- 再找出这些人参与的作品,到crew表中得到title_id
- 到ratings表中得到投票数,到titles表中找到作品名
- 按照投票数降序排列,取前10名
- 格式
Top Gun|408389
1 | |
问题7 [15分] (q7_year_of_thieves):
列出与“Army of Thieves”同年首播的作品数量。
**详:**仅打印作品总数。答案应该包括 “Army of Thieves”本身。对于这个问题,通过title_id确定不同的作品,而不是他们的名字。
1 | |
查询步骤:
先得到Army of Thieves的播放年份
然后查询与这个年份同一年播放的所有作品的title_id
数一下
1 | |

问题8 [15分] (q8_kidman_colleagues):
找出曾与 Nicole Kidman 合作出演(出演同一部作品)的所有演员和女演员的名字。
输出格式要求如下:
- 只输出
name(不包含 id 或其他字段); - 按字母表排序;
- 不允许重复(所以需要用
DISTINCT); - 包含 Nicole Kidman 本人!
判断某人是否在某部作品中“出演”,需要看 crew 表里的 category 字段;
其中,“actor” 和 “actress” 是两种不同的角色标签;
所以你必须同时找 category = ‘actor’ 和 category = ‘actress’ 的人(不能只找其中一种);
1 | |
查询逻辑:
- 在people表中得到Nicole Kidman的person_id
- 然后在crew表中找到与Nicole Kidman有相同的title_id的人,查看他是actor还是actress,回到people找到人名
- 我们可以通过自然连接把people表和crew表连接起来
1 | |
这里要注意的是NK可能参演了多部作品,这个时候title_id是用 IN 而不能用等号
1 | |
问题 9 [15 分] (q9_9th_decile_ratings):
找出所有 出生于 1955 年 的人,获取他们的名字,以及他们职业生涯中参与过的电影的 平均评分。
输出这些人中职业平均评分位于第 9 分位数(decile)的人的名字和平均评分。
详:计算 1955 年出生的每个人的平均评分 只有他们参与过的电影。计算每个分位数 使用 NTILE(10) 的个人平均评分。
确保您的输出格式如下(将平均评分四舍五入为 最接近的百分之一,结果应按复合值 他们的评级降序,其次是他们的名字,按字母顺序排列):Stanley Nelson|7.13
**注意:**您应该在处理平均职业后取分位数个人的电影评级。换句话说,找到那些拥有职业生涯电影的平均评分在所有人的第 9 个十分位数。
查询步骤:
- 找到所有出身于1955年的人,获取名字(people表)、职业生涯中演过的电影(crew表)的平均评分(ratings表)
1 | |
1 | |
内层查询先计算每个人的平均评分和所在十分位 decile;
外层查询只筛选第 9 十分位 (decile = 9);
拼接输出格式为 名字|评分,评分四舍五入保留两位小数;
问题10 [15分] (q10_house_of_the_dragon):
请将《House of the Dragon》这部剧的所有独特标题(title)拼接成一个按字母顺序排列、逗号 + 空格分隔的单个字符串csv。
查找 TV 节目名称为
"House of the Dragon"的所有标题(包括被翻译/配音后的标题,即 dubbed titles)。去重,区分大小写(
"foo"和"Foo"被视为不同)。按字母升序排列这些标题。
使用 逗号 + 空格(
,) 作为分隔符,将所有标题拼接成一个字符串返回。推荐使用 递归 CTE(WITH RECURSIVE) 实现字符串拼接。
最终输出是一个单行字符串,如:
foo, Hello World, zzz
1 | |