DB_Lec3
查询处理
查询处理步骤: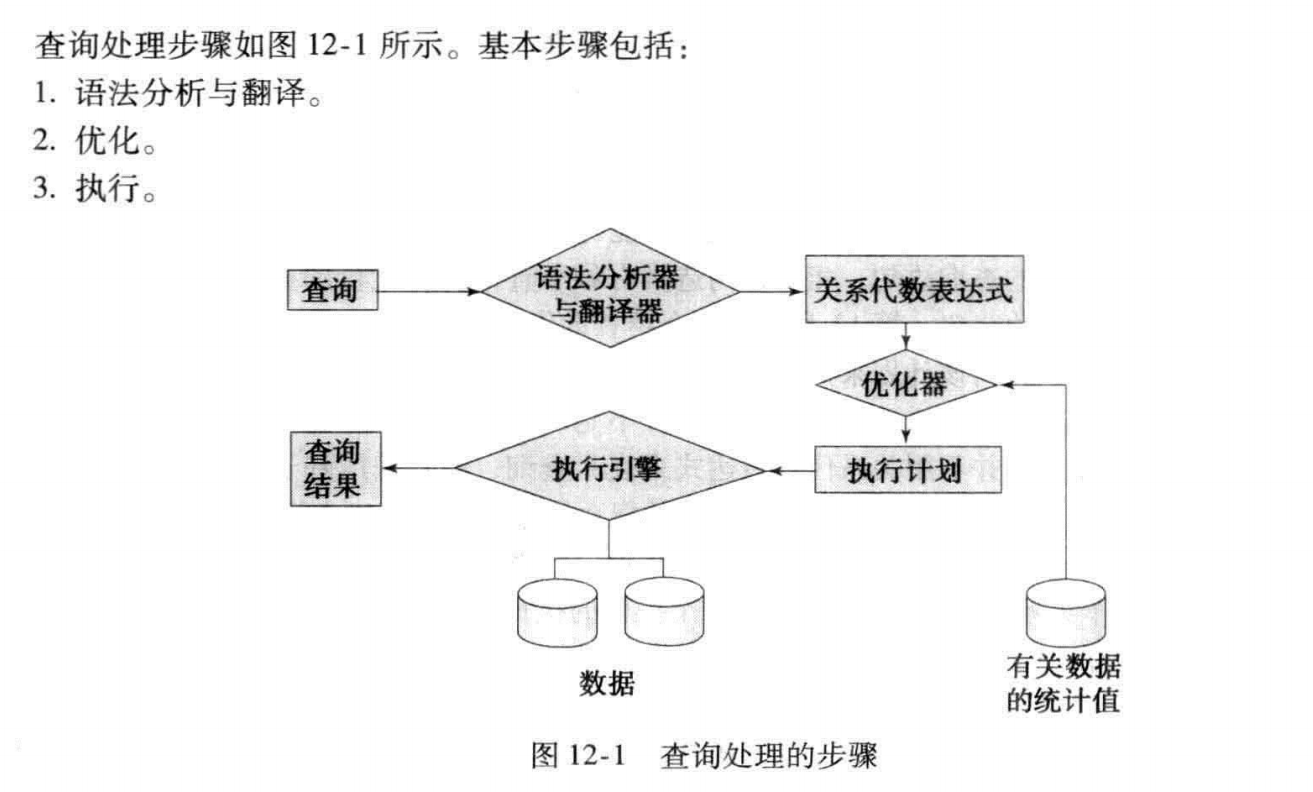
顺序索引
聚集索引:包含记录的文件按照某个搜索码指定的顺序排序,那么该搜索码对应的索引称为聚集索引
- 聚集索引页称为主索引
非聚集索引:搜索码指定的顺序与文件中记录的物理顺序不同的索引
稠密索引和稀疏索引
- 稠密索引是指文件中的每个搜索码值都有一个索引项。
- 在稠密聚集索引中,索引项包括搜索吗值以及指向具有搜索码值的第一条数据记录的指针。
- 有相同搜索码值的其余记录顺序地存储在第一条数据记录之后
- 稀疏索引:只为搜索码的某些值建立索引项。
- 只有当关系按搜索码排列顺序存储时才能使用稀疏索引=>只有索引是聚集索引时才能使用稀疏索引
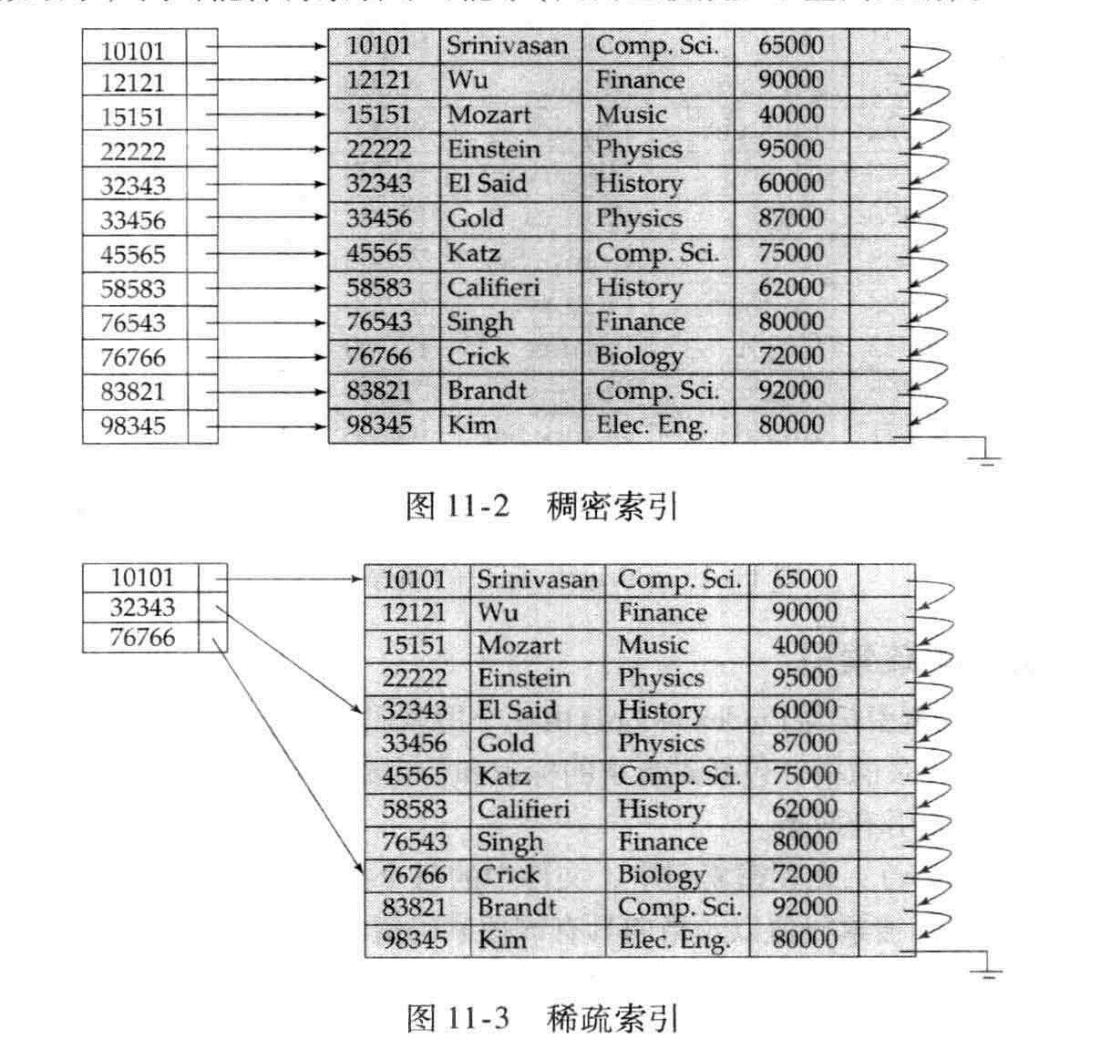
- 只有当关系按搜索码排列顺序存储时才能使用稀疏索引=>只有索引是聚集索引时才能使用稀疏索引
多级索引
- 节约存储空间
数据库存储基础
存储层次与设备类型
- 和计组、os中讲述的类似
存储层次:金字塔 - 靠近CPU的存储设备速度最快、容量最小、价格最高(如寄存器、高速缓存)
- 离CPU越远的存储设备速度越慢、容量越大、价格越低(如内存、SSD、HDD)
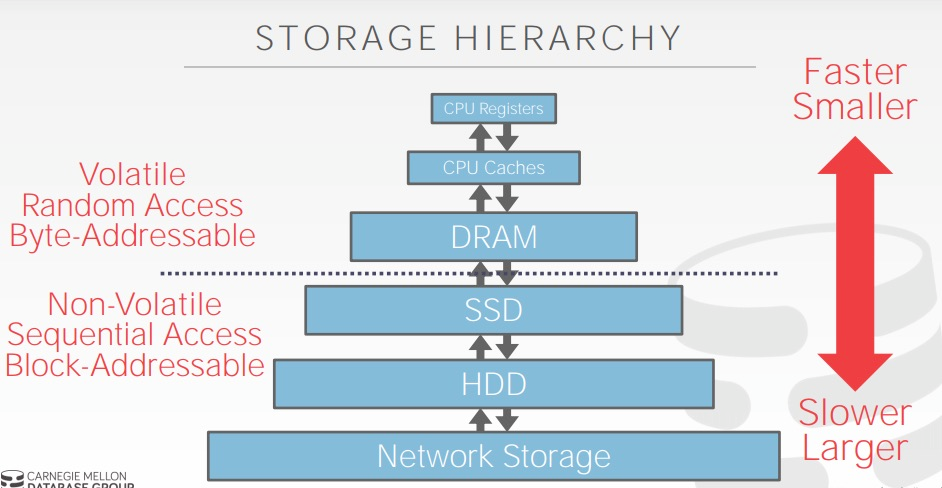
易失性设备(内存):
- 断电后数据丢失
- 支持字节寻址的快速随机访问
- 典型代表:DRAM
非易失性设备(磁盘):
- 断电后数据保留
- 块/页寻址(通常4KB页大小)
- 传统上更适合顺序访问
- 包括SSD和HDD,课程中统称为”磁盘”
新兴技术:
- 持久内存(如Intel Optane):接近DRAM速度+磁盘持久性(但未广泛使用)
- NVMe SSD:使用改进接口的传统NAND闪存,提供更快传输速度、
面向磁盘的DBMS架构
传统的DBMS架构属于面向磁盘的架构,所以DBMS中一般都有磁盘管理模块,主要负责数据在非易失与易失的存储器之间移动
核心概念:
数据库完全存储在磁盘上(保证非易失,且量大)
数据组织为固定大小的页(第一个页是目录页–页表)
缓冲池管理数据在磁盘和内存间的移动
执行引擎通过缓冲池访问数据页
磁盘延迟对比如果L1缓存访问需要1秒:
- SSD访问需要4.4小时
- HDD访问需要3.3周
为什么需要将数据在不同的存储器之间移动?
- 磁盘管理模块的存在是为了同时获得易失性存储器的性能和非易失性存储器的容量,让DBMS的数据看起来像在内存中一样
为什么要自己来做数据移动的管理,而非利用 OS 自带的磁盘管理模块?
- DBMS 比 OS 拥有更多、更充分的知识来决定数据移动的时机和数量
- 将 dirty pages 按正确地顺序写到磁盘
- 根据具体情况预获取数据
- 定制化缓存置换(buffer replacement)策略
DBMS与OS的关系
关键区别
- DBMS需要管理超过内存大小的数据库
- 不能因磁盘I/O导致整个系统停滞
- 类似虚存概念,但是DBMS需要更多控制
为什么不使用mmap
- 写入操作不可靠
- 遇到页错误时进程会被阻塞
- DBMS比OS更了解数据访问模式

文件存储与页组织
基本概念
- 数据库存储为磁盘文件,OS把它们当做普通文件
- 只有DBMS能解释文件内容
- 存储管理器负责文件管理和页组织(DBMS不会自己造文件系统)
数据库页
- 固定大小块
- 包含不同数据类型
- 三种页概念
- 硬件页(通常4KB)
- OS页(通常4KB)
- 数据库页(1-16KB)
不同DBMS管理pages的方式不同
- 堆文件组织
- heap file 指的是一个无序的 pages 集合,pages 管理模块需要记录哪些 pages 已经被使用,而哪些 pages 尚未被使用。
- 顺序文件组织
- 哈希文件组织
页标识与存储
- 唯一页ID
- 可能使用间接层映射页ID到文件路径和偏移量
- 固定大小页简化工程实现
原子写入保证
- 硬件页大小决定原子写入单位
- 数据库页大于硬件页时,需要额外机制保证崩溃安全
堆文件组织
堆文件概念
- 无序页集合
- 元组随机存储
两种定位方式
链表
- 头页包含空闲页和数据页指针
- 查找特定页需要顺序扫描
pages管理模块维护一个header page,后者维护两个page列表–空闲页表和数据页表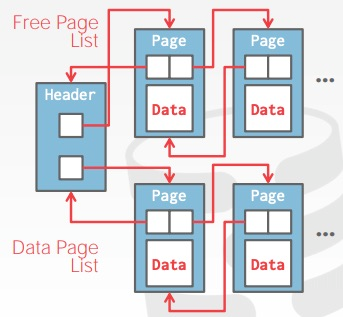
页目录
- 特殊页记录数据页位置和空闲空间
- 更高效的随机访问
| 方法 | 优点 | 缺点 |
|---|---|---|
| 链表 | 简单实现 | O(n)查找复杂度 |
| 目录 | O(1)查找 | 需要额外空间维护目录 |
页布局与元组存储
页头部信息
- 页大小、校验和、DBMS版本
- 事务可见性信息
- 自包含信息(某些系统如Oracle需要)
数据记录方式
Tuple-oriented:记录数据本身
- 在header中记录tuple的个数,然后不断往下append即可

- 在header中记录tuple的个数,然后不断往下append即可
缺点:
- 一旦出现删除操作,每次插入就要遍历一次,寻找空位,否则会出现空间浪费
- 无法处理变长的数据记录
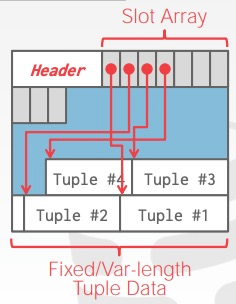
slotted pages
- header中的slot array记录每个slot的信息,如大小、位移等
- 新增记录时,在slot array中新增一条记录,记录着改记录的入口地址。slot array 与 data 从 page 的两端向中间生长,二者相遇时,就认为这个 page 已经满了
- 删除记录时:假设删除 tuple
#3,可以将 slot array 中的第三条记录删除,并将 tuple #4 及其以后的数据都都向下移动,填补 tuple #3 的空位。而这些细节对于 page 的使用者来说是透明的 - 处理定长和变长 tuple 数据都游刃有余
Log-structured:记录数据的操作日志
- 只存储日志记录

- 每次记录新的操作日志即可,增删改的操作都很快,但有得必有失,在查询场景下,就需要遍历 page 信息来生成数据才能返回查询结果。为了加快查询效率,通常会对操作日志在记录 id 上建立索引,如下图所示:
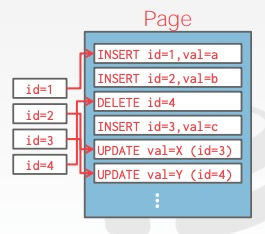
- 写快,读慢
- 只存储日志记录
两种主要布局方式
- 槽式页
- 最常用
- 头部记录已用槽数、最后使用槽偏移
- 槽数组记录每个元组的起始位置
- 元组从页尾向前增长,槽数组从页头向后增长
- 日志结构
- 只存储修改日志而非直接存储元组
- 通过反向扫描日志重建元组
- 写入快但读取可能慢
- 需要定期压缩(形成SSTables)
- 存在写放大问题
元组布局
- 头部:可见性信息、NULL位图
- 数据:按创建表时指定的顺序存储属性
- 唯一标识符:通常为page_id+offset/slot

存储时: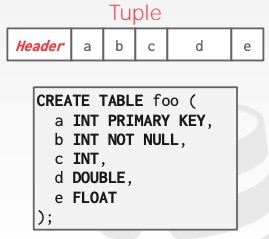
数据库支持的数据类型包含
- INTEGER/BIGINT/SMALLINT/TINYINT
- FLOAT/REAL vs. NUMERIC/DECIMAL
- VARCHAR/VARBINARY/TEXT/BLOB
- TIME/DATE/TIMESTAMP
FLOAT/REAL/DOUBLE
vs
NUMERIC/DECIMAL
float,real,double类型的数字按照IEEE-754标准存储,都是固定精度的,无法保证精确度要求很高的计算的正确性;
如果希望允许数据精确到任意精度,则可以使用numeric/decimal类型类存储,它们就像varchar一般,长度不定。
- 大部分的DBMSs不允许一个tuple中的数据超过一个page大小,如果实在要存储这样子的large values,就会使用overflow或者Toast page
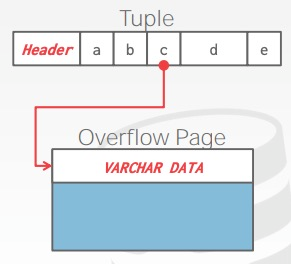
- 一些 DBMSs 甚至允许你在外部存储二进制大文件,即 BLOB,但 DBMSs 一般不会负责管理外部文件,没有 durability protections 和 transaction protections,而且数据库的 dump 操作不会对外部文件起作用,转移数据时需要单独处理。
反规范化数据:
- 预连接相关表到同一页
- 加快读取(减少页加载)但增加更新成本
数据库存储高级主题
日志结构存储详解
传统槽式页设计问题:
- 碎片化:删除元组产生页内空隙(页内碎片)
- 无用磁盘I/O:必须读取整个块获取单个元组
- 随机磁盘I/O:更新分散在不同位置效率低
日志结构存储特点
- 仅追加写入,无覆盖
- 存储数据库修改日志而非直接存储元组
- 通过索引快速定位记录(如LSM树)
- 定期压缩减少读取开销
系统目录
除了数据本身,DBMS还需要存储数据的元数据,即数据字典。
[!NOTE]
元数据——关于数据的数据
用来描述数据的特征、背景、结构或管理方式,但本身并不是数据的具体内容
元数据是数据的’tag’
作用:
- 解释数据
- 组织数据
- 管理数据
- table, columns, indexes, views
- users, permissions
- internal statistics
查询元数据,我们之前做hw1时使用过:
1 | |
OLTP&OLAP
OLTP:联机事务处理Online Transaction Processing
OLAP:联机分析处理Online Analytical Processing
OLTP:主要用于日常业务事务处理,如银行转账、订单创建、库存管理等,支持高并发、实时的小规模数据增删改操作,确保事务的ACID特性(原子性、一致性、隔离性、持久性)。
OLAP:用于复杂的数据分析和决策支持,如生成报表、趋势分析、市场预测等,基于数据仓库多维模型(如星型或雪花模型),支持多维数据查询(如切片、切块、钻取等),侧重于历史数据和大数据量的聚合分析。
数据存储模型
关系数据模型将数据的attributes组合成tuple,将结构相似的tuple组合成relation,但是没有指定他们的存储方式
常见的数据存储模型:
- 行存储 N-ary Storage Model (NSM)

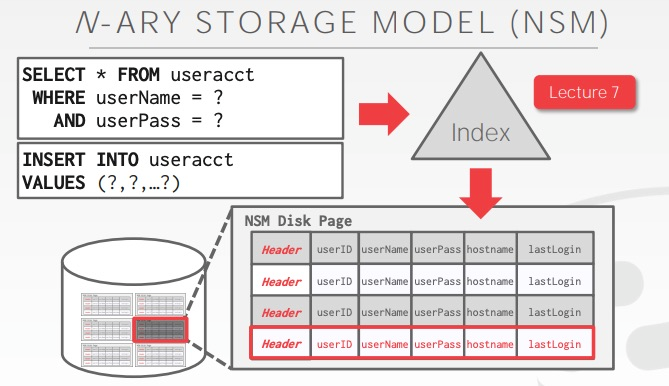
NSM的优缺点
优点:
高效插入、更新、删除,涉及表中小部分tuples
有利于需要整个tuple的查询
列存储 Decomposition Storage Model (DSM)
列存储会将所有tuples的单个attribute连续地存储在一个page中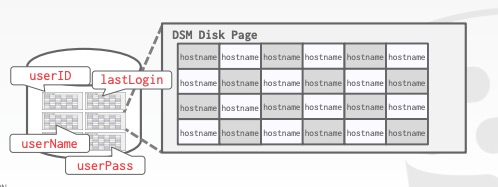
如何跟踪每个 tuple 的不同 attributes?可能的解决方案有:
- Fixed-length Offsets:每个 attribute 都是定长的,直接靠 offset 来跟踪(常用)
- Embedded Tuple Ids:在每个 attribute 前面都加上 tupleID
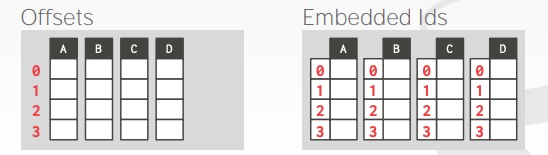
总结一下,DSM 的优缺点如下:
- Advantages
- 减少 I/O 操作
- 更好的查询处理和数据压缩支持
- Disadvantages
- 涉及少量 tuples、多数 attributes 的查询低效