Java_basic
二哥的Java进阶之路x沉默王二 | 二哥的Java进阶之路
基础概念
JDK、JRE和JVM分别都是什么?
JDK:开发java应用程序的软件环境
JRE:运行java应用的软件环境
JVM:java的虚拟机,屏蔽了不同os的差异性。可以一次编译,到处运行
顺便学到了用chocolate来安装!不用再手动设置path了!
.class文件和.java源代码的关系?
- .class是字节码文件,是经过javac编译后的文件,是交给jvm执行的文件。
- .java是源代码
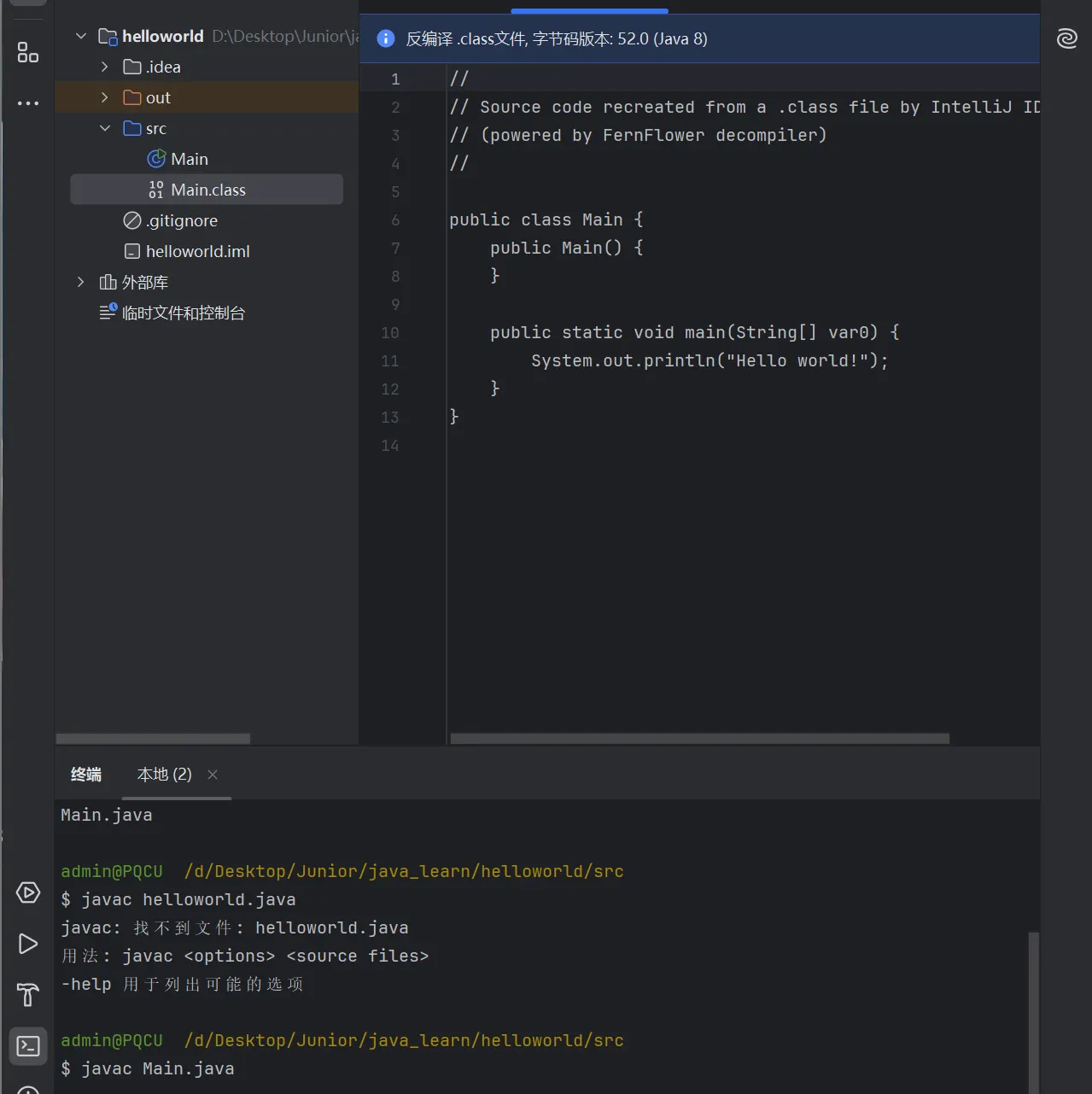
可以通过javac Main.java这个命令来讲.java编译成.class
可以使用java命令运行字节码:如 java Main
- 字节码由JVM逐条解释执行
- 部分字节码可能由JIT编译为机器指令直接执行
逐条执行是JVM的基本执行模式。在这种模式下,Java 虚拟机会逐条读取字节码文件中的指令,并将其解释为对应的底层操作。
- 优点:实现简单,启动速度快,但效率低
JIT即时编译:在 JIT 模式下,Java 虚拟机会在运行时将频繁执行的字节码编译为本地机器码,这样就可以直接在硬件上运行,而不需要再次解释。
- 需要注意的是,JIT 编译器并不会编译所有的字节码,而是根据一定的策略,仅编译被频繁调用的代码段(热点代码)。
- 优点:执行效率高,编译热点代码,动态优化
现代的JVM通常会结合这两种执行方法,在程序运行初期,采用前者,减少启动时间;随着程序的运行,JVM会识别出热点代码并采用JIT 编译器讲其编译为本地机器码,从而提高程序的执行效率(混合模式)
- 为了跨平台,java源代码首先编译成字节码。
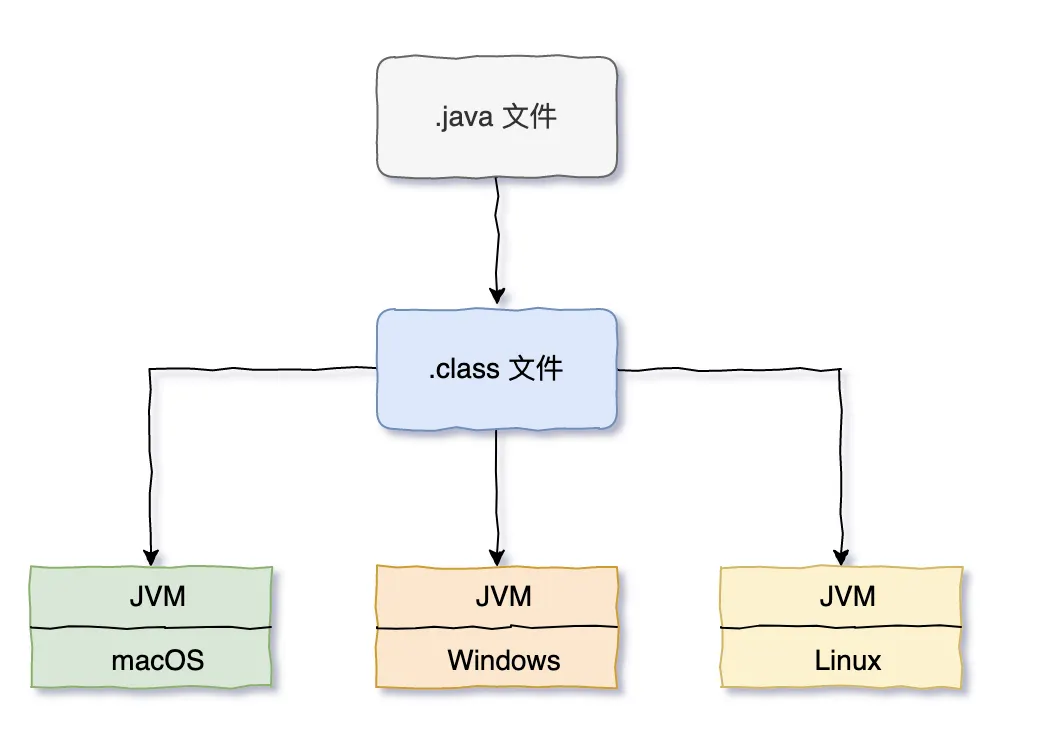
数据类型
java是一种静态类型的编程语言,也就是说所有变量必须在使用前声明好,且必须先制定并变量的类型和名称。(cpp也是静态类型的编程语言)
- 基本数据类型
- boolean、char、byte、short、int、long、float 和 double
- 引用数据类型
- 数组、class、接口
变量:局部变量(必须先初始化)、成员变量和静态变量(后两个可以不进行初始化,因为它们会有一个默认值)
- 数组、class、接口
- 比如int,成员变量和静态变量如果没有进行初始化,值会为0.
| 数据类型 | 默认值 | 大小 |
|---|---|---|
| boolean | false | 不确定 |
| char | ‘\u0000’ | 2 字节 |
| byte | 0 | 1 字节 |
| short | 0 | 2 字节 |
| int | 0 | 4 字节 |
| long | 0L | 8 字节 |
| float | 0.0f | 4 字节 |
| double | 0.0 | 8 字节 |
基本数据类型
- boolean:ture,false
情况1: - 对于单独使用的boolean,JVM没有提供专用的字节码指令,而是使用int相关的istore来处理,此时的boolean占用4bytes
- 但作为数组使用的boolean类型,JVM会按照byte的指令来处理,此时的boolean占用1byte
情况2:布尔具体占用的大小是不确定的,取决于 JVM 的具体实现。
单个boolean变量:
对象头占用了12bytes
- OFFSET 0 - 4:对象头的一部分,包含对象的标记字段(Mark Word),用于存储对象的哈希码、GC 状态等。
- OFFSET 4 - 8:对象头的另一部分,通常是指向类元数据的指针(Class Pointer)。
- OFFSET 8 - 12:对象头的最后一部分,包含锁状态或其他信息。
- 实际的boolean值占用1byte(offset12-13)
- 为了满足 8 字节的对齐要求(HotSpot JVM 默认的对象对齐方式),有 3 个字节的填充。OFFSET 13 - 16。
所以尽管boolean的值只需要1byte,但实际上占用了16bytes
boolean数组:假设arr[10]
同样的,对象头占用了12bytes
- OFFSET 0 - 4:对象头的一部分,包含对象的标记字段(Mark Word)。
- OFFSET 4 - 8:对象头的另一部分,包含指向类元数据的指针(Class Pointer)。
- OFFSET 8 - 12:对象头的最后一部分,通常包含数组的长度信息。
数组长度 占用了 4 个字节,此处是 10,OFFSET 12 - 16。
实际的boolean值值占用了1byte,offset:16-26
同时要凑够2的幂次
[!NOTE]
对象头主要由mark word(标记字段)和klass pointer(类型指针)组成
由于其他的和cpp很类似,所以跳过。
包装器类型(wrapper types)
- java中的一种特殊类型,用于将基本数据类型转换为对应的对象类型
Java 提供了以下包装器类型,与基本数据类型一一对应:
- Byte(对应 byte)
- Short(对应 short)
- Integer(对应 int)
- Long(对应 long)
- Float(对应 float)
- Double(对应 double)
- Character(对应 char)
- Boolean(对应 boolean)
e.g:
1 | |
引用数据类型
- 对于接口类型的引用变量来说,没有办法直接new一个。
- 只能new一个实现它的类的对象
- 变量名指向存储对象的内存地址(在栈上)
- 内存地址指向的对象存储在堆上 (动态的)
数据类型转换
自动类型转换
一般发生在求值、做运算的时候,比如double和int,一般会往大的转(类型自动提升)。
- 自动类型转换只发生在兼容类型之间。
1 | |
需要注意:
1 | |
这里的50虽然是int,但是在赋值给b的时候,(如果这个赋值在byte类型的取值范围内)编译器会做隐式转换。
强制类型转换
- 需要我们显式地指定要执行的转换。
一般出现在:
- 较大数据类型转换为较小的数据类型(可能导致精度丢失)
- 将浮点数转换为整数
- 将字符类型转换为数值类型
注意:
1 | |
int sum = a + b;这一条,由于int a和int b相加会超过范围,导致越界,变成负数- 第二条,虽然最后赋值到long sum1,但是在右边计算的时候,两个int相加依然在int范围内,计算出结果之后,结果再赋值给long(这个时候转换不会越界–long比int范围更大)
- 第三条,由于这里a先转换为了long,所以b也会呗转换为long,在右边不会发生越界。
- 第四条,由于我们先计算了括号里的(a+b)再把结果转换为long,所以会越界,其实和第二条是差不多的。
结果:
1 | |
基本数据类型缓存池(IntegerCache)
看下下面的代码:
1 | |
[!NOTE]
首先我们需要注意,java中==对于基本类型比较的是值,但是对于引用类型比较的是内存地址
现在再来看,由于 new Integer() 会创建一个新的对象,所以这里的x和y指向的内存地址一定是不同的(所以这里会打印false)
而 Integer.valueOf() 会使用缓存,对于 -128~127的整数,返回缓存中的同一个对象。所以这里18在范围内,返回的是同一个对象,但是300不在范围内,valueOf会创建新的Integer对象,所以m、p指向不同的对象。
最后的输出情况:
1 | |
具有常量缓存池的类型(注意:float和double没有–浮点数范围太大了)
| 数据类型 | 缓存池范围 |
|---|---|
| Byte | -128~127 |
| Short | -128~127 |
| Long | -128~127 |
| Character | \u0000 - \u007F |
| Boolean | True、False |
- valueOf的源码:
1 | |
可以看到,如果超出范围,会调用new来创建
断言(asseert)–调试工具,用于检查程序逻辑
(默认关闭)需要手动启动:
1 | |
assert:
1 | |
运算符
包括:算术运算符、关系运算符、位运算符、逻辑运算符、赋值运算符、三元运算符
算术运算符
- 也就是
+ - * / %和++,--
关系运算符
==,!=,<,>,<=,>=,
位运算符
&,|,^,~,<<,>>,>>>
与cpp不同的是:>>>:按位右移补零,左操作数的值按右操作数指定的位数右移,移动得到的空位以0填充
左移相当于乘2,右移相当于除以2
逻辑运算符
逻辑与运算符(&&):多个条件中只要有一个为 false 结果就为 false。
逻辑或运算符(||):多个条件只要有一个为 true 结果就为 true。
逻辑非运算符(!):用来反转条件的结果,如果条件为 true,则逻辑非运算符将得到 false。
单逻辑与运算符(&):很少用,因为不管第一个条件为 true 还是 false,依然会检查第二个。
单逻辑或运算符(|):也会检查第二个条件。
&&和&用法差不多,但是前者会导致短路,而后者不会(性能差一点)
赋值运算符
这个很常见
三元运算符
和cpp一样
e.g:int min=(a<b)?a:b;
控制语句
简单看了一下和cpp几乎一样
pass
- 有点忘记(用于遍历数组或集合)
1 | |
尝试写一下
- 实现翻转
1 | |
但是我这个版本并没有做溢出检查,所以最好是在计算前检查是否会溢出,即补充:
1 | |
数组和字符串
数组
声明:
1 | |
初始化:
1 | |
- 数组是一个对象(上面使用了new)
访问数组
可变参数数组
java中,可变参数用于将任意数量的参数传递给方法
1 | |
- 必须使用
...表示,必须是参数列表中的最后一个参数(在方法内部被当作数组处理)
例子:
1 | |
数组和List
- list封装了很多常用的方法,可以把数组转换成List来使用这些方法。
转换方法:
- 遍历数组
1 | |
- 通过Arrays类的
asList()方法:
1 | |
- Arrays.asList的参数需要是Integer数组
- 所以我们需要把原本的arr转换。
(1) 方法一
1 | |
(2) 方法二
1 | |
- 先将数组转换为Stream(IntStream–基本int类型的流)
- 如果
anArray是int[],得到的是IntStream - 如果
anArray是Integer[],得到的是Stream<Integer>
- 如果
- 然后将int转换为Integer(包装)
- 最后收集为List
Arrays.asList()返回的是Arrays类的内部类ArrayList,不是我们常用的 java.util.ArrayList:
- 不支持add(),remove()等修改大小的操作
- 支持get(),set()等读取操作
如果要把这种内部类转换为我们常用的类:
1 | |
数组的查找与排序
java也有sort()方法
- 升序
- 实现了 Comparable 接口的对象按照
compareTo()的排序
使用例子:
1 | |
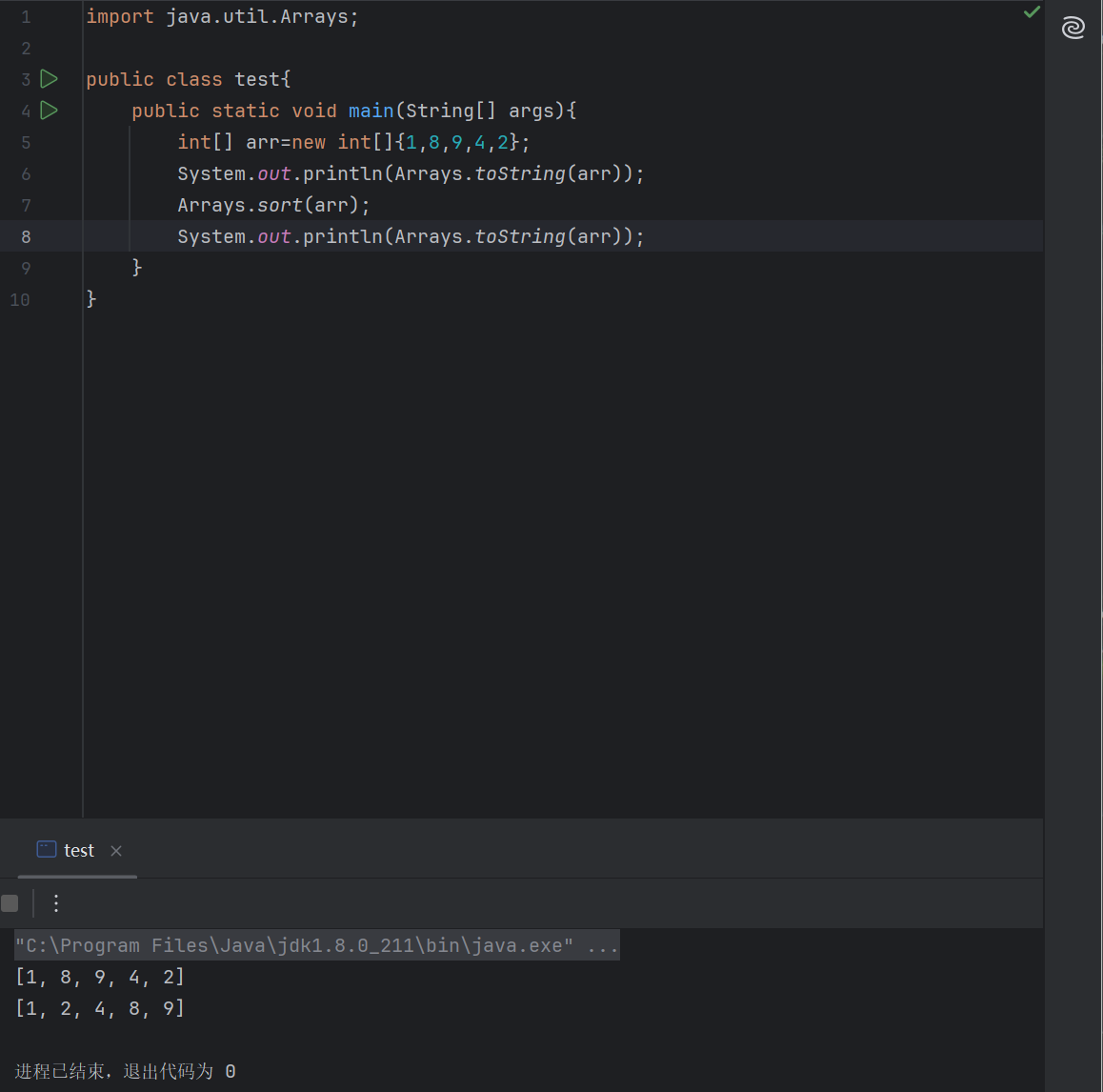
要注意这里打印,
- 不能像python一样直接print(arr);如果直接print(arr)会输出arr的地址,而不是里面的值。
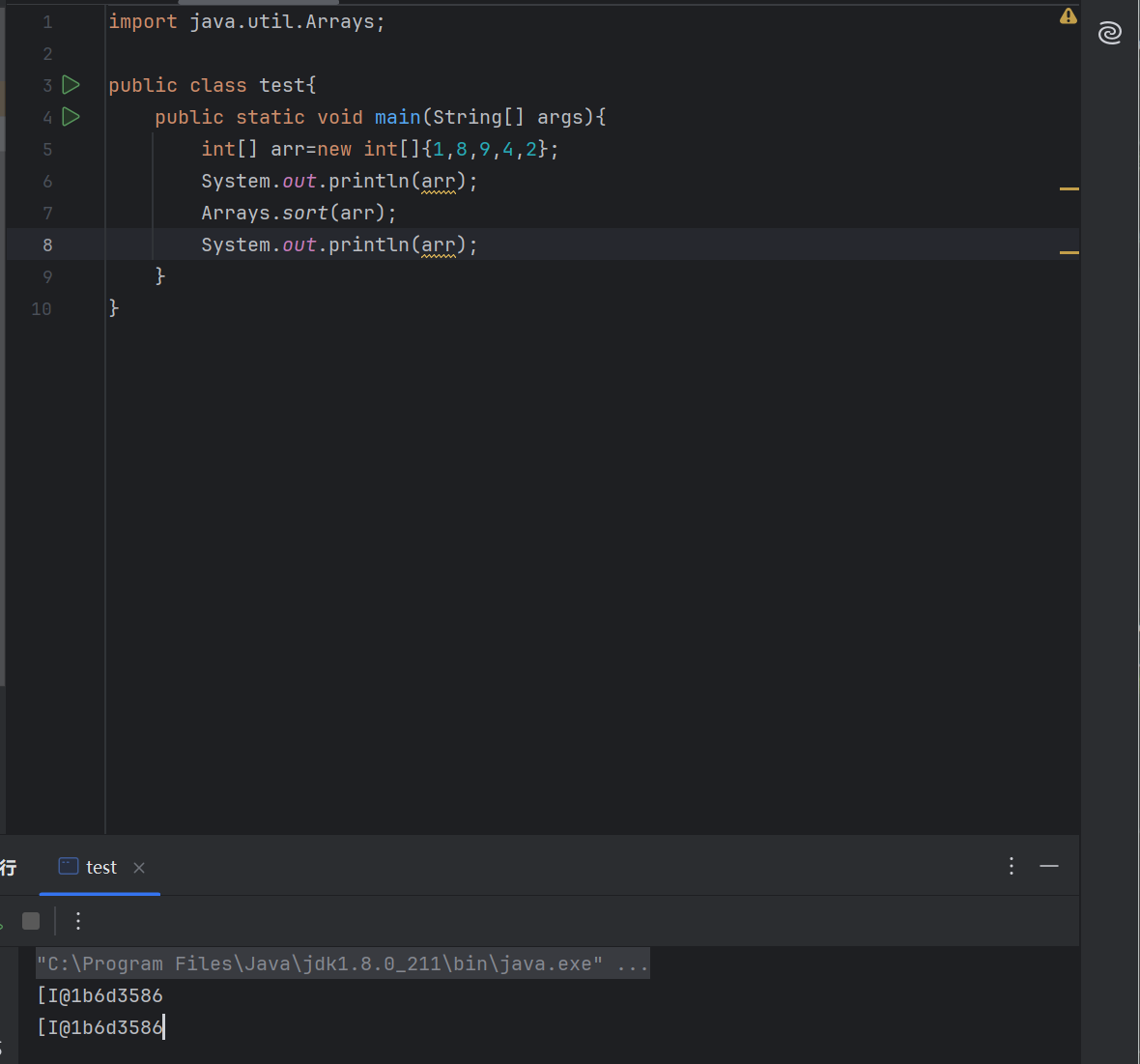
- 顺便认识一下这个地址打印出来的格式
[表示一维数组,[[表示二维数组I表示数组元素类型是int@是分隔符- 剩下的部分是对象的哈希码(十六进制)
部分排序:
1 | |
这里对1-3进行排序Comparator.comparing(String::toString).reversed():自定义比较器
比较器:
1 | |
java中还提供了二分查找 Arrays.binarySearch()方法,参数是一个数组和需要查找的元素。
数组的复制
Arrays.copyOfRange()用于复制数组- 其底层调用的是
System.arraycopy()方法–native方法
二维数组
1 | |
字符串
String类的声明
1 | |
- String类是final的(即不可被继承、不可重写)
- Serializeable接口:可以序列化
- Comparable接口:定义了一些比较方法,比如比较两个字符串是否相等,使用
compareTo()–可以比较值 - 实现了
CharSequence接口(String,StringBuffer,StringBuilder都实现了)
String也定义了 equals(Object obj),用于判断两个字符串的内容是否完全相同
- 实现思路:先判断是否是同一个对象->检查obj是否是String类的实例(不是则强制转换)->检查字符串长度->遍历比较每个字符
compareTo(Str anotherStr):定义自然顺序。判断一个字符串在字典序上是大于、等于还是小于另一个字符串。(返回值:0,负整数,正整数)
[!NOTE]
String底层为什么由char数组优化为byte数组?
- 为了节省内存!
优化为byte[] 之后,引入了编码标志(coder)来智能选择存储方式。- 有两种编码方式(LATIN1(只包含拉丁字母,1byte)和UTF-16(非拉丁字符,2bytes))
hashCode方法
1 | |
- 31倍哈希法
substring
用于提取子串。
- 实现思路:检查是否越界,不越界则创建一个新的对象(new String(value,begin,subLen);)
1 | |
使用方法:
1 | |
输出:
1 | |
PS:trimmed.split("\\s+");
这里的\\s+是在进行正则匹配,\s 表示的是任意空白字符(空格、tab、换行、回车),+(量词),前面的元素出现一次or多次。
- 由于
\s是转义字符,所以这里要多加一个反斜杠
indexOf方法
- 用于查找一个子字符串在原字符串中第一次出现的位置,并返回该位置的索引。
1 | |
String 类的其他方法
①、比如说 length() 用于返回字符串长度。
②、比如说 isEmpty() 用于判断字符串是否为空。
③、比如说 charAt() 用于返回指定索引处的字符。
④、比如说 valueOf() 用于将其他类型的数据转换为字符串。
valueOf实际上调用的是包装器类的toString方法,比如说整数转为字符串用的是Integer类的 toString
⑥、比如说 getBytes() 用于返回字符串的字节数组,可以指定编码方式
⑦、比如说 trim() 用于去除字符串两侧的空白字符
⑧、比如说 toCharArray() 用于将字符串转换为字符数组。
[!NOTE]
需要注意的是,接口和抽象类是不可以实例化的,具体类可以。
比如说,Map,List,Set是接口,不可以// Map<String, Integer> map = new Map<>(); // ❌ 错误!
但是HashMap,ArrayList,HashSet是具体类,可以Map<String, Integer> map = new HashMap<>(); // ✅ 正确
java字符串是不可变的。
1 | |
string类的数据存储在 char[] 数组里,这个数组被final修饰了,说明只要初始化了,值就固定了。
- 保证了String对象的安全性
- 保证哈希值不会频繁变更
- 可以实现字符串常量池,Java 会将相同内容的字符串存储在字符串常量池中。
字符串常量池
Q1:下面这行代码创建了几个对象?
1 | |
- 乍一看好像只创建了一个对象,但实际上创建了两个对象。
使用new关键字创建一个字符串对象时,JVM会先在字符串常量池中查找是否存在,如果有就不会在字符串常量池中创建这个对象了,直接在堆里创建一个字符串对象,然后将堆里的这个对象地址返回赋值给变量s
如果没有,先在字符串常量池中创建一个字符串对象,然后在堆里创建一个对象,最后将堆里的这个字符串对象的地址返回赋值给s
- 总之,最后两个地方会存在这个对象,一个是字符串常量池,另一个是堆。返回进行赋值的总是堆里的这个对象。
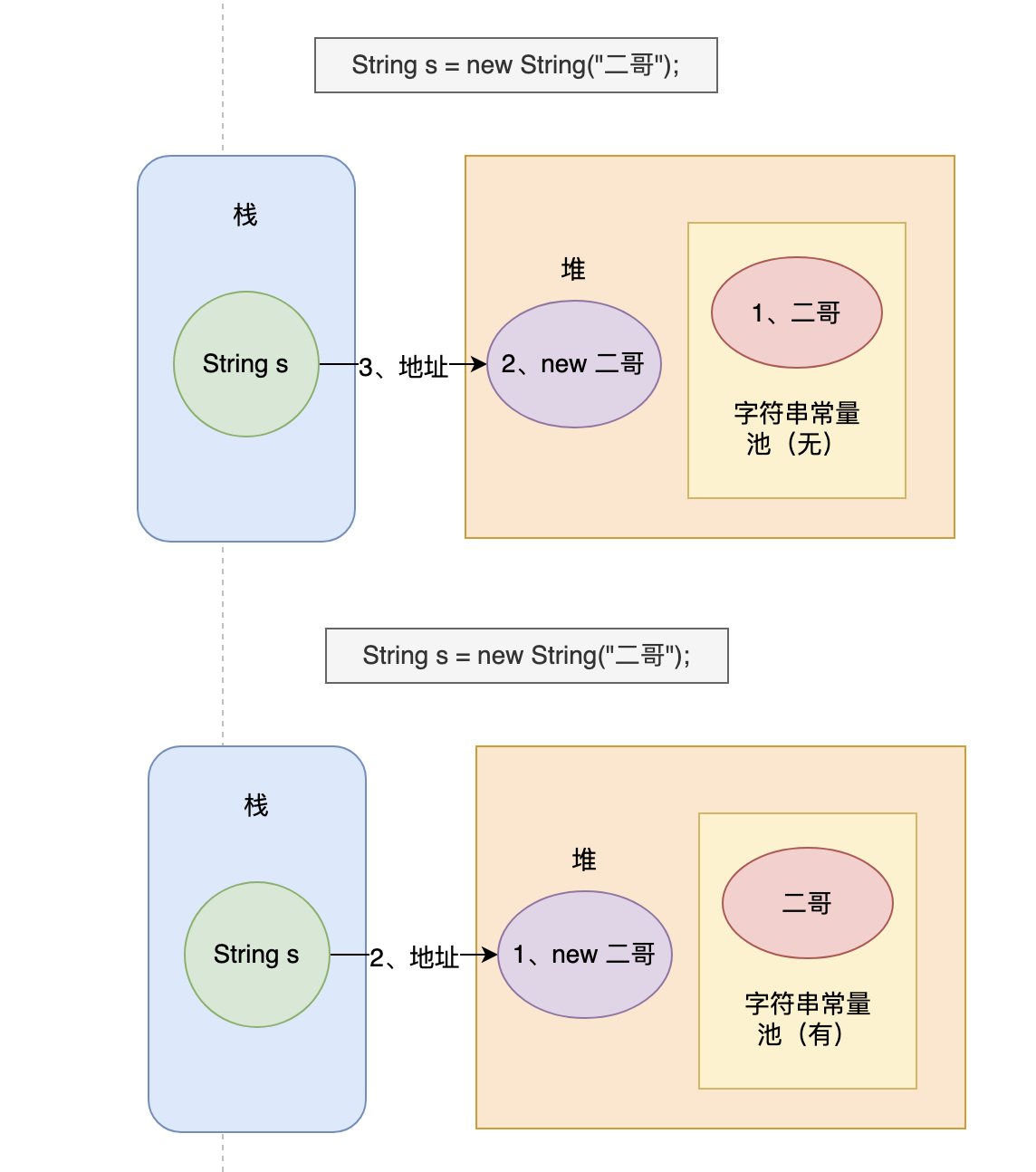
通常情况下,我们会采用双引号的方式来创建字符串对象,而不是通过new。这样子就不会像上面一样创建两个对象了。
1 | |
当执行上述指令时,JVM会先在字符串常量池中查找有没有这个字符串对象,如果有就不创建任何对象,直接将字符串常量池这个对象地址返回,赋给变量s;如果没有就在字符串常量池中创建这个对象,然后将这个对象地址返回。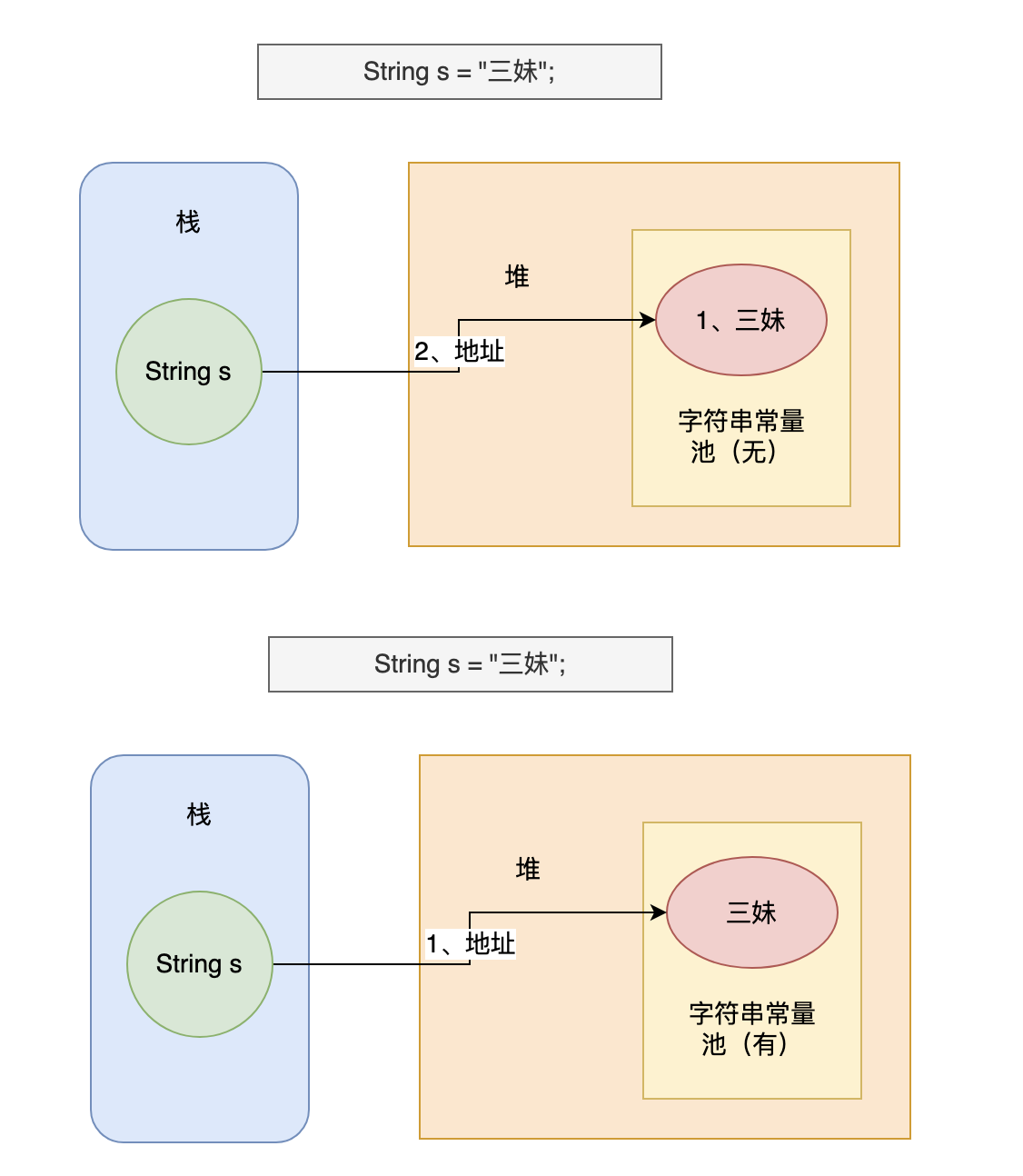
例子:
1 | |
这两行代码会创建3个对象!
首先new一定会创建一个,其次最开始在字符串常量池中不存在,则会再创一个
1 | |
这两行代码只会创建1个对象!
字符串常量池在内存中的什么位置?
java7之前,位于永久代内存区。主要用来存储字符串常量。(永久代是 Java 堆(Java Heap)的一部分,用于存储类信息、方法信息、常量池信息等静态数据。)
- 永久代时java堆的一个子区域
- 永久代中存储的静态数据与堆中存储的对象实例和数组是分开的,它们有不同的生命周期和分配方式。
java7之后,字符串常量池移动到堆中。
java8之后,永久代被取消了,由元空间取代。(元空间时本机内存区域,和jvm内存区域是分开的)
intern
我们上面提到:String类型的常量池比较特殊。它的主要使用方法有两种:
- 直接使用双引号声明出来的
String对象会直接存储在常量池中。 - 如果不是用双引号声明的
String对象,可以使用String提供的intern方法。intern 方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中
1 | |
例子,这里 intern()方法会从字符串常量池中查找这个字符串是否存在,存在那么s2的地址就会来自字符串常量池的那个对象。
但是s1的地址是堆上那个对象的地址,所以它们的地址不同,会返回false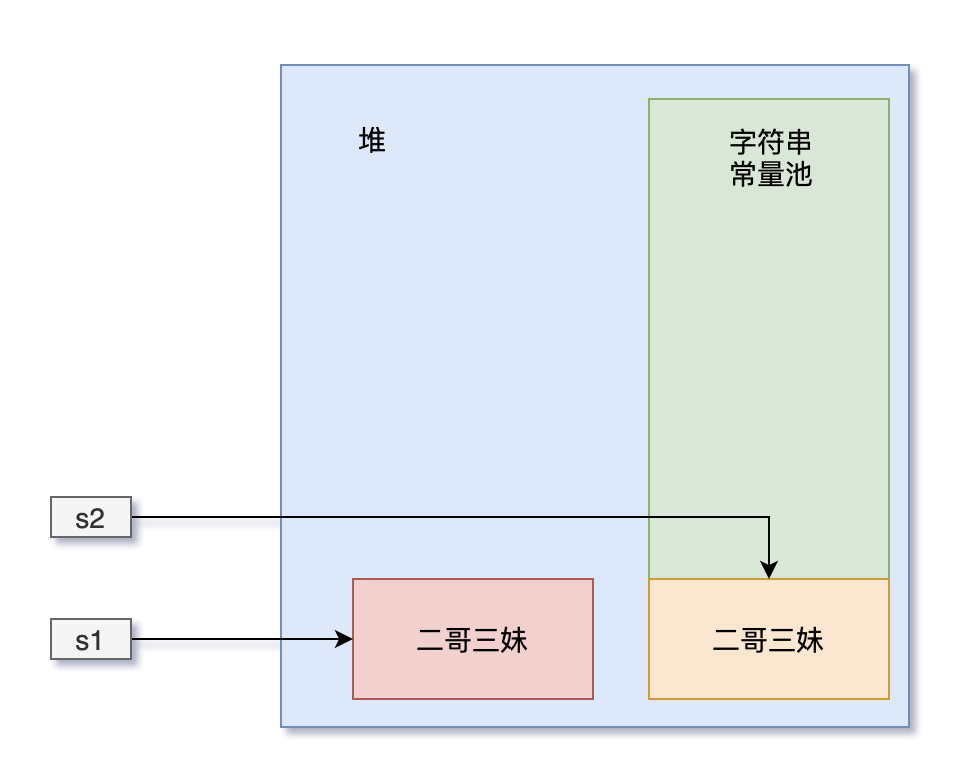
1 | |
但是这段会输出true
第一行会在字符串常量池中创建两个对象,然后在堆上创建两个匿名对象“二哥”,“三妹”,最后还有一个“二哥三妹”的对象。s1引用的是“二哥三妹”这个对象。
第二行代码,会在字符串常量池查找“二哥三妹”这个对象是否存在,发现并不存在,但堆上已经存在了,所以字符串常量池中保存的是对上的这个对象的引用!
所以s1和s2的地址相同。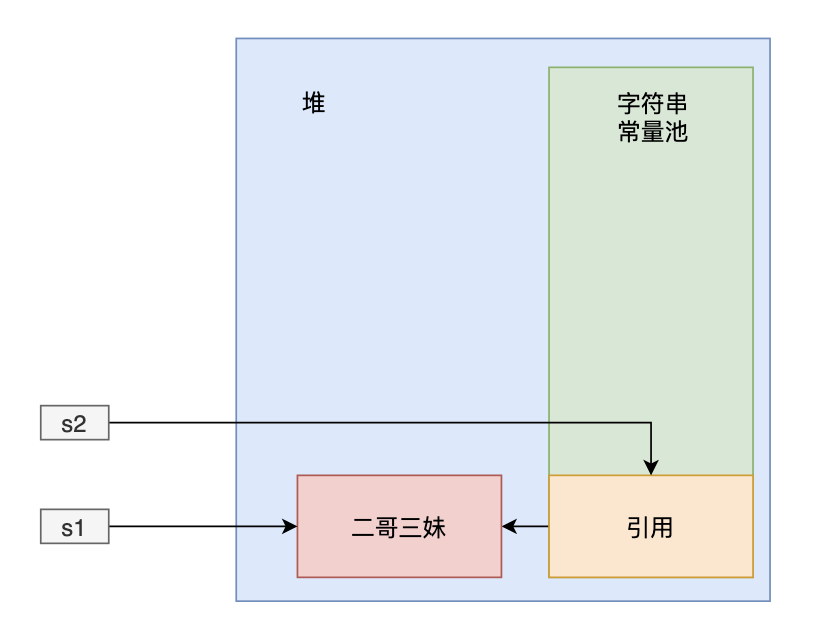
StringBuilder和StringBuffer
由于字符串是不可变的(之前提到过有final),所以当遇到字符串拼接时,需要考虑性能问题(不能毫无顾虑生产太多string对象,对珍贵的内存造成不必要的压力)
1 | |
第二行代码看起来是修改了str,但实际上发生了三件事:
- 创建了一个新的String对象
- 将变量str的引用指向这个对象
- 原来的“Hello”对象会等待垃圾回收器回收
这两个类都是可变的字符序列,也就是可以对同一个对象进行修改,而不会创建新的对象。
这两个类有相同的API
append(): 在末尾追加内容。insert(): 在指定位置插入内容delete(): 删除指定范围内的字符。reverse(): 反转字符序列。toString(): 转换为不可变的String对象。
它们之间的唯一区别是:
StringBuffer有线程安全,但是StringBuilder没有。
- StringBuffer的方法都由
synchronized关键字修饰。可以适用于多线程环境,即多个线程可以同时操作同一个对象。 - StringBuilder 方法没有同步,适用于单线程环境。
我们之前学计组的时候学到,多线程环境下,我们做一些操作需要保证“原子性”,所以很多时候会去上锁。那这个上锁的过程会导致了性能比较低。
所以在单线程情况下,我们最好使用StringBuilder,避免加没必要的锁
其实有时候我们会无意中使用到了StringBuilder。由于java时一门解释性语言,在编译的时候,编译器会帮我们做很多优化。
比如在做字符串拼接时(使用 + ),编译器会把他变成:
1 | |
判断字符串相等
两种办法,一个是使用 .equal() 方法,另一个是使用 == 操作符
它们的区别是:
.equal()方法用于比较两个对象的内容是否相等,也就是值是否相等==方法用于判断两个对象的地址是否相等
但是!Object类的.equal()方法默认采用==操作符进行比较。如果子类没有重写这个方法,那这两个效果是一样的。
字符串里我们更希望判断值是否相等,所以String类重写了这个方法。
1 | |
首先判断是否是对象本身(使用 == 来判断地址是否相等)
如果不是:
if (anObject instanceof String) {进行类型检查,看是否是String类)- 检查完之后,如果是就可以将其显示转换为tring类。
if (coder() == aString.coder()) {编码格式检查,用于比较两个字符串的内部编码相同。
练习
1 | |
输出true,因为内容是相同的
1 | |
输出false,因为这里比较的是地址
左边是在堆中创建的对象,右边是在字符串常量池中创建的对象。
- 我们之前学到,new String这样子会导致在堆和字符串常量池中都创建对象,最后返回的是堆上的对象的地址。右边的方法会先在字符串常量池中查找是否存在这样子的对象,如果存在返回字符串常量池里的对象
1 | |
返回false。
new出来的对象地址不同
1 | |
返回true
跟我们刚刚说的一样,返回的都是字符串常量池里的对象
1 | |
返回的还是true
“由于‘小’和‘萝莉’都在字符串常量池,所以编译器在遇到‘+’操作符的时候将其自动优化为“小萝莉”,所以返回 true。”
1 | |
new String("小萝莉") 在执行的时候,会先在字符串常量池中创建对象,然后再在堆中创建对象;
执行 intern() 方法的时候发现字符串常量池中已经有了‘小萝莉’这个对象,所以就直接返回字符串常量池中的对象引用了,那再与字符串常量池中的‘小萝莉’比较,当然会返回 true 了。
这里 intern()方法会从字符串常量池中查找这个字符串是否存在。
判断字符串对象是否相等的其他方法
Objects.equals()
这个方法的好处是不需要在调用之前判空
使用:
1 | |
- String类的
.contentEquals()
这个方法可以将字符串与任何的字符序列(StringBuffer、StringBuilder、String、CharSequence)进行比较
拼接字符串
循环体内拼接字符串最好用 StringBuilder 的 append() 方法而不是 + 操作符,因为在循环体里如果采用 + 操作符,会产生大量的StringBuilder对象,会占用很多内存空间,并让JVM不停地进行垃圾回收。
还有一些方法:
- String.concat拼接字符串
- String.join
可以将第一个参数作为字符串连接符
1 | |
输出:王二-太特么-有趣了
拆分字符串split()
注意:split的参数是正则表达式!
比如:
1 | |
因为 . 在正则表达式中表示任意字符,需要转义
需要修改为:
1 | |
还有一个要注意的:
空字符串会被丢弃
1 | |
这里的多个分隔符被当作一个分隔符了
如果确实需要保留空字符串,可以这样子:
1 | |
这个-1属于limit参数。split(regex, limit)的 limit 参数行为复杂:
| limit 值 | 行为描述 | 示例 "a,b,c,,,".split(",", limit) |
|---|---|---|
limit > 0 |
最多分成 limit 个部分 | limit=2→ ["a", "b,c,,,"] |
limit = 0 |
默认行为,丢弃末尾空字符串 | ["a", "b", "c"] |
limit < 0 |
不限制次数,保留所有空字符串 | ["a", "b", "c", "", "", ""] |
正则表达式:
cdoco/learn-regex-zh: :cn: 翻译: 学习正则表达式的简单方法
常用的正则表达式:
cdoco/common-regex: :jack_o_lantern: 常用正则表达式 - 收集一些在平时项目开发中经常用到的正则表达式。